The MLP Problem
Every transformer layer has two main components: attention heads that move information between positions, and MLPs that apply nonlinear transformations at each position. We have good tools for analyzing attention -- the QK and OV decomposition reveals how heads select and process information. MLPs, by contrast, remain opaque. They are dense, nonlinear, and difficult to decompose into interpretable parts.
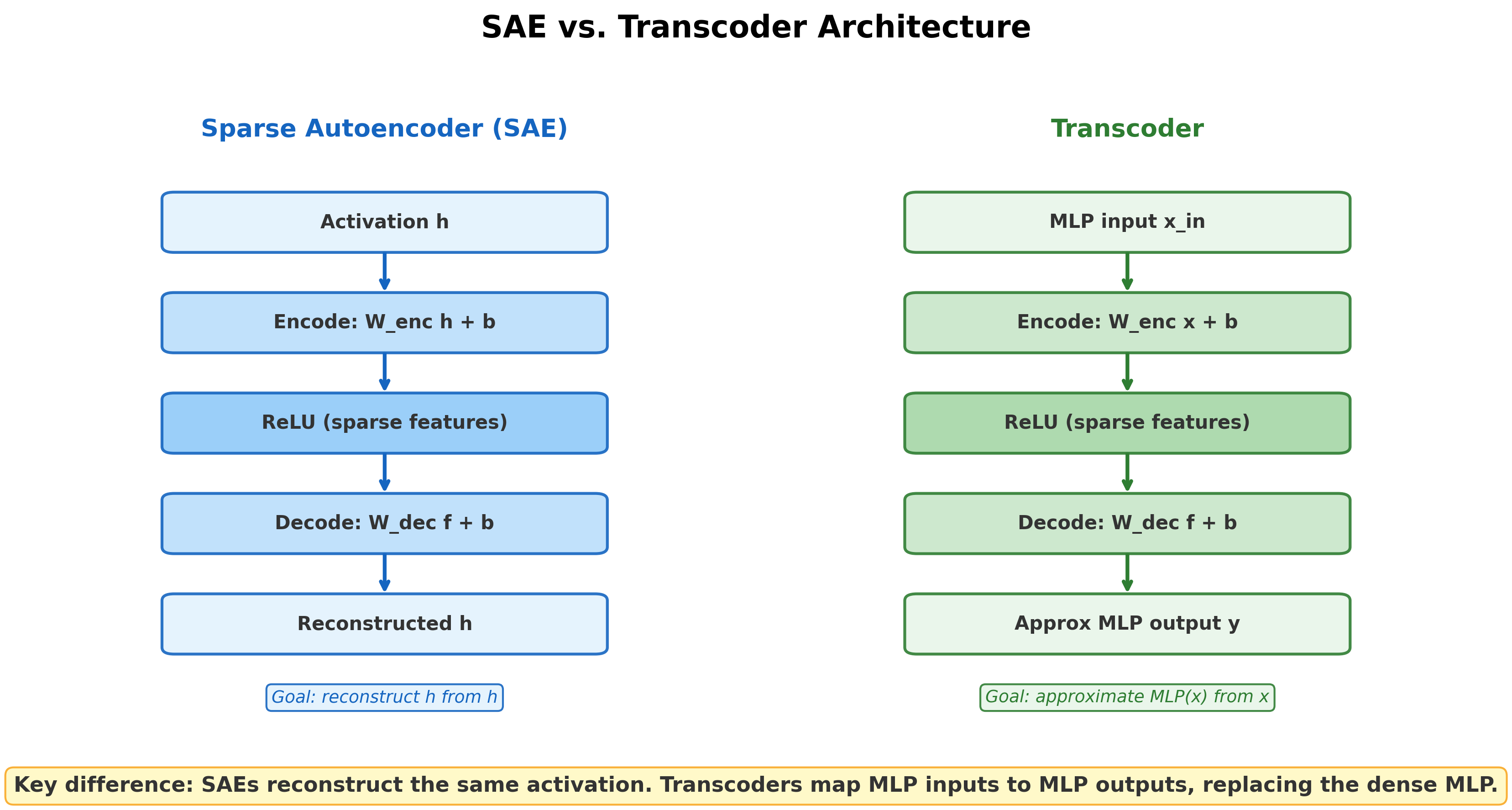
Sparse autoencoders offered a partial solution. By training an SAE on a layer's activations, we can decompose those activations into sparse, interpretable features. But SAEs reconstruct the same activation they receive as input. They reveal what features are present at a given layer, not how information transforms as it passes through the MLP. An SAE placed at the MLP output tells us what features exist after the MLP computation. It does not tell us which input features produced which output features.The distinction is subtle but important. An SAE asks: 'What features are encoded in this activation vector?' A transcoder asks: 'What function does this MLP compute, expressed in terms of sparse features?' The first is a question about representation; the second is a question about computation.
For circuit analysis, we need to trace causal paths through MLP layers, not just observe what comes out the other side. This is what transcoders provide.
What Is a Transcoder?
Transcoder: A transcoder is a modified sparse autoencoder that approximates MLP behavior. Instead of encoding and reconstructing the same activation, a transcoder takes the MLP input and produces an approximation of the MLP output :
The transcoder replaces the dense MLP with a wider, sparsely-activating layer.
The architecture mirrors an SAE in structure -- encoder, sparse bottleneck, decoder -- but the input and output differ. An SAE maps . A transcoder maps , where is what enters the MLP and is what the MLP would produce. The transcoder learns to approximate the MLP's function, not its representation.
Why This Matters for Circuits
The difference between SAEs and transcoders is exactly what enables feature-level circuit analysis:
SAEs decompose what a layer represents. Given activation , an SAE finds sparse features such that . This is useful for understanding individual layers but does not reveal how features at one layer produce features at the next.
Transcoders decompose what a layer computes. Given MLP input , a transcoder finds sparse features that produce the MLP output. Because the transcoder's features map inputs to outputs, we can trace how upstream features contribute to downstream features through the MLP.In the residual stream picture, attention heads move information between positions while MLPs transform information at each position. SAEs decompose the residual stream at a point. Transcoders decompose the transformation that happens between points. Both are needed for complete circuit analysis.
This means we can trace causal paths through MLP layers, not just around them. Before transcoders, circuit analysis could follow information through attention (which is linear in its inputs) but had to treat each MLP as a black box.
Clean Factorization
Dunefsky et al. (2024) showed that transcoder circuits factorize cleanly into two terms [1]Transcoders Find Interpretable LLM Feature Circuits
Dunefsky, J., Chlenski, P., Nanda, N.
NeurIPS, 2024:
- An input-dependent term: which transcoder features activate on this particular input
- An input-invariant term: how feature activations map to outputs through the decoder weights
This factorization is powerful because it means we can do weights-based circuit analysis through MLP sublayers. The decoder weights tell us, for any given feature, exactly what direction it writes to the output -- regardless of the input. The encoder tells us which features fire for a given input. Together, they give a complete, interpretable account of what the MLP computes on that input.
Dunefsky et al. applied transcoders to GPT-2 Small's greater-than circuit -- the circuit that processes prompts like "The war started in 1742 and ended in 17__". Transcoders revealed sub-computations within the circuit that were invisible at the head level, showing that the circuit was more modular than previously understood.
Pause and think: SAEs vs. transcoders
SAEs reconstruct the same activation they receive. Transcoders map MLP inputs to MLP outputs. Why does this difference matter for tracing how information flows through a network?
Think about what it means to follow a causal chain from input to output. At each transformer layer, attention moves information between positions (traceable, since attention is linear), and then the MLP transforms it (opaque). An SAE at the MLP output tells you what features exist after the transformation, but not how they got there. A transcoder exposes the transformation itself: which input features caused which output features. Without transcoders, MLP layers are gaps in the circuit diagram.
Transcoders vs. SAEs: A Direct Comparison
Paulo et al. (2025) conducted a head-to-head comparison of transcoders and SAEs trained on the same model and data. The results were striking:
- Transcoder features are significantly more interpretable than SAE features. The interpretability advantage is consistent across evaluation methods.
- Skip transcoders -- transcoders with an added affine skip connection -- achieve lower reconstruction loss with no reduction in interpretability. This is a Pareto improvement: better reconstruction and equal interpretability.
- On SAEBench evaluation tasks (including feature absorption and sparse probing), transcoders show improved quality.
The implication is clear: SAEs were the first-generation tool for decomposing superposition, but transcoders may be the next. SAEs remain valuable for understanding what features a layer represents, but for understanding what a layer computes -- and for tracing circuits through MLPs -- transcoders are the better tool.This does not mean SAEs are obsolete. SAEs and transcoders answer different questions. SAEs ask 'What features are present?' Transcoders ask 'What function is computed?' For applications like feature dashboards and automated interpretability, SAEs may still be the right choice. For circuit analysis, transcoders have a structural advantage.
From Transcoders to Circuit Tracing
Transcoders solve a specific problem: making MLP computations interpretable. But the real payoff comes when transcoders are combined with attention-based analysis to trace complete circuits at the feature level.
Marks et al. [2]Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, S., Rager, C., Michaud, E. J., et al.
ICLR 2025, 2024 demonstrated that SAE features can serve as the nodes in causal circuit graphs -- sparse feature circuits. This was an important step, but the approach still relied on per-layer SAEs and computationally expensive patching.
Lindsey et al. [3]Circuit Tracing: Revealing Computational Graphs in Language Models
Lindsey, J., Batson, J., Denison, C., et al.
Anthropic, 2025 took the next step with attribution graphs: replacing all MLPs in a model with cross-layer transcoders and tracing circuits backward through the entire feature network using the Jacobian. The result is a complete, feature-level circuit map for any given input.
The progression is natural: transcoders make MLPs interpretable, sparse feature circuits show that SAE features can be circuit nodes, and attribution graphs combine both ideas at scale. Circuit Tracing and Attribution Graphs covers sparse feature circuits and attribution graphs in detail.
Pause and think: What changes with feature-level circuits?
In the IOI circuit analysis, the circuit had 26 attention heads as nodes. With transcoders enabling feature-level analysis, circuits can have thousands of feature nodes. What do we gain from this higher resolution? What do we lose?
We gain interpretability at each node -- features are (mostly) monosemantic, while attention heads are polysemantic. We gain the ability to trace through MLPs, not just around them. But we lose simplicity: a 26-node circuit diagram can be drawn and understood at a glance, while a 2,000-node feature graph requires careful pruning and visualization tools to make sense of.
Key Takeaways
- SAEs decompose representations; transcoders decompose computations. This distinction is what enables circuit tracing through MLP layers.
- Clean factorization into input-dependent and input-invariant terms allows weights-based analysis of MLP sublayers.
- Transcoders outperform SAEs on interpretability benchmarks while enabling circuit analysis that SAEs structurally cannot provide.
- Transcoders are the enabling technology for attribution graphs and feature-level circuit tracing, covered in Circuit Tracing and Attribution Graphs.