The Fundamental Tension
In earlier articles on circuit analysis, features aligned neatly with individual attention heads. A Name Mover head moved names. An S-Inhibition head suppressed repeated subjects. Each component had one clear role, and we could study the model one head at a time. But what happens when features do not align with heads, when a single head participates in multiple unrelated computations, and a single feature is distributed across many components?
This is not a pathological edge case. It is the default.
Why Neurons Are Polysemantic. Early vision interpretability work found neurons that fired for both wolves and Coca-Cola cans. The model had learned to reuse the same neuron for unrelated concepts because they never co-occurred in training data. This is efficient for the model but disastrous for interpretation: if you think you have found the "wolf neuron" and test it on wolves, it fires. But you do not know it also fires for cans. Ablation experiments become unreliable. Claims about what neurons represent become unfounded.
The same phenomenon appears in language models. A neuron might fire for "baseball" and "academic citations." A head might participate in five different circuits for five different tasks. The clean one-to-one mapping between components and concepts that would make interpretability easy simply does not exist in most models.
The reason is a counting problem at the heart of neural network representations.
Consider a language model with a residual stream of dimension . If each feature gets its own orthogonal direction, the model can represent at most 512 features. But language understanding requires far more than 512 features. The model needs to track syntax, semantics, entities, relationships, sentiment, factual knowledge, and more. There are plausibly millions of features that a model would benefit from representing.The term 'feature' here means any property of the input that the model finds useful for prediction. A feature might be 'this token is a proper noun,' 'the sentence is a question,' 'the subject is plural,' or 'the text is discussing sports.' Features range from simple syntactic properties to complex semantic and factual associations.
The fundamental tension is stark:
A 512-dimensional residual stream has 512 orthogonal directions. But the model might need to represent 10,000 or 100,000 distinct features. What does the model do?
There are two strategies. The first is to select the top features by importance, give each one its own orthogonal direction, and ignore everything else. This produces zero interference between features, but many features are lost entirely. The second is to pack more features into the available dimensions by using non-orthogonal directions. This represents more features but introduces noise: features that share dimensions interfere with each other.
Superposition: A neural network exhibits superposition when it represents more features than it has dimensions by encoding features as non-orthogonal directions in activation space. Features share dimensions, causing interference: activating one feature partially activates others.
Superposition is not a design choice. It is an emergent property that arises from training when the model has more useful features than available dimensions. Whether the model adopts superposition depends on two factors: how important each feature is (high-importance features are worth dedicating a dimension to) and how sparse each feature is (rare features interfere less often, as we will see). The interplay between importance and sparsity determines the model's strategy, and studying this interplay is the central contribution of the toy model framework [1]Toy Models of Superposition
Elhage, N., Hume, T., Olsson, C., et al.
Anthropic, 2022.
Where Superposition Lives: Privileged and Non-Privileged Bases
Before we study superposition in a toy model, we need to understand a subtlety that changes where and how superposition manifests. Not all activation spaces in a transformer are created equal. The difference comes down to whether the nonlinearity treats each dimension individually.
Why ReLU creates a privileged basis. In an MLP, a vector enters the hidden layer, gets multiplied by to produce a pre-activation vector, and then ReLU zeroes out the negatives independently for each dimension. This elementwise operation makes each axis special. Suppose the hidden layer is 3-dimensional and the pre-activation is . ReLU produces : neuron 1 is "on," neuron 2 is "off," neuron 3 is "on." Each neuron has its own gate. The nonlinearity treats the axes individually, so the axes are the natural units of analysis.
Privileged basis: An activation space has a privileged basis when the model's computation treats each coordinate axis differently, typically because a nonlinear activation function (like ReLU or GELU) is applied elementwise. In a privileged basis, individual dimensions (neurons) are meaningful units of analysis.
Why the residual stream has no privileged basis. All operations that read from and write to the residual stream are linear: attention output is a linear function of value vectors, MLP output is added linearly, and queries, keys, and values are computed via linear projections. The key argument is a symmetry one: if you rotate the entire residual stream by an orthogonal matrix (and adjust all writing matrices to include and all reading matrices to include ), the model's computation and output are identical. To see this concretely, consider a query projection: becomes , which equals the same result. This rotation invariance means "dimension 42 of the residual stream" is not a meaningful concept. You could rotate it away without changing anything the model computes.
Non-privileged basis: An activation space has a non-privileged basis when any orthogonal rotation of the space, with corresponding adjustments to input and output matrices, leaves the model's computation unchanged. In a non-privileged basis, individual dimensions carry no inherent meaning; only directions matter.
Pause and think: Does rotating the MLP hidden layer preserve computation?
Consider an MLP hidden layer with ReLU activation. If you rotate the hidden layer activations by an orthogonal matrix , does the MLP compute the same function? Think about what ReLU does to a rotated vector versus the original.
It does not. ReLU applied to is not the same as applied to . Rotation mixes dimensions, and then ReLU zeroes out different entries than it would have in the original basis. For example, if and is a 45-degree rotation, but , which gives a different result when rotated back. The elementwise nonlinearity breaks rotation invariance, creating the privileged basis.
This distinction produces two flavors of superposition with different consequences:
- MLP hidden layers have a privileged basis. Individual neurons are meaningful units, but each one may serve multiple roles. Neuron 42 fires for "sports" and "the color red." We can see individual neurons, but they are not monosemantic. This is computational superposition: the right units of analysis are clear (neurons), but each unit is overloaded.
- The residual stream has no privileged basis. There are no meaningful individual dimensions at all. Features exist as directions, but no basis is special. Looking at "dimension 42" is as arbitrary as looking at "the average of dimensions 17 and 93." This is representational superposition: even the units of analysis are unclear.
The practical consequences are direct. When MI researchers say "neuron 42 in layer 6 fires for X," they are relying on the privileged basis: each neuron has its own activation gate that makes it individually meaningful. When they say "there is a direction in the residual stream that encodes sentiment," they cannot point to any single dimension because the residual stream has no privileged basis. This is also why sparse autoencoders behave differently depending on where they are trained: applied to the MLP hidden layer, an SAE decomposes neurons into finer-grained features; applied to the residual stream, it decomposes the whole space into features, since there are no natural units to start from.
The Toy Model
To study superposition systematically, Elhage et al. built a toy model that isolates the core question: given features and dimensions, how does the network allocate directions? [2]Toy Models of Superposition
Elhage, N., Hume, T., Olsson, C., et al.
Anthropic, 2022
The architecture is deliberately simple. The input is a vector with features, each with known importance and sparsity. A linear encoder maps this from down to (the bottleneck), a ReLU nonlinearity is applied, and a linear decoder maps back to :
Why a toy model? Real transformers are too complex to study superposition directly. The toy model isolates the core representational question by giving us direct control over two experimental knobs. Feature importance controls how much each feature matters for the reconstruction loss -- high importance means reconstruction errors on that feature are costly, while low importance means the model can afford to sacrifice accuracy. Feature sparsity controls how often each feature is active -- high sparsity () means the feature is almost never active, while low sparsity () means it is active most of the time. Because is small (2D or 3D), we can visualize the learned representations directly.
The model minimizes weighted reconstruction error:
where is the importance of feature and the expectation is over the data distribution, which determines how often each feature is active. This setup lets us ask precisely: given these importances and sparsities, does the trained model use superposition?
Phase Diagrams
Elhage et al. trained many toy models, varying feature importance and sparsity systematically [3]Toy Models of Superposition
Elhage, N., Hume, T., Olsson, C., et al.
Anthropic, 2022. For each model, they measured whether the learned representation used superposition (non-orthogonal feature directions) or dedicated dimensions (orthogonal directions). The result is a phase diagram: a map showing where in the importance-sparsity space superposition occurs.
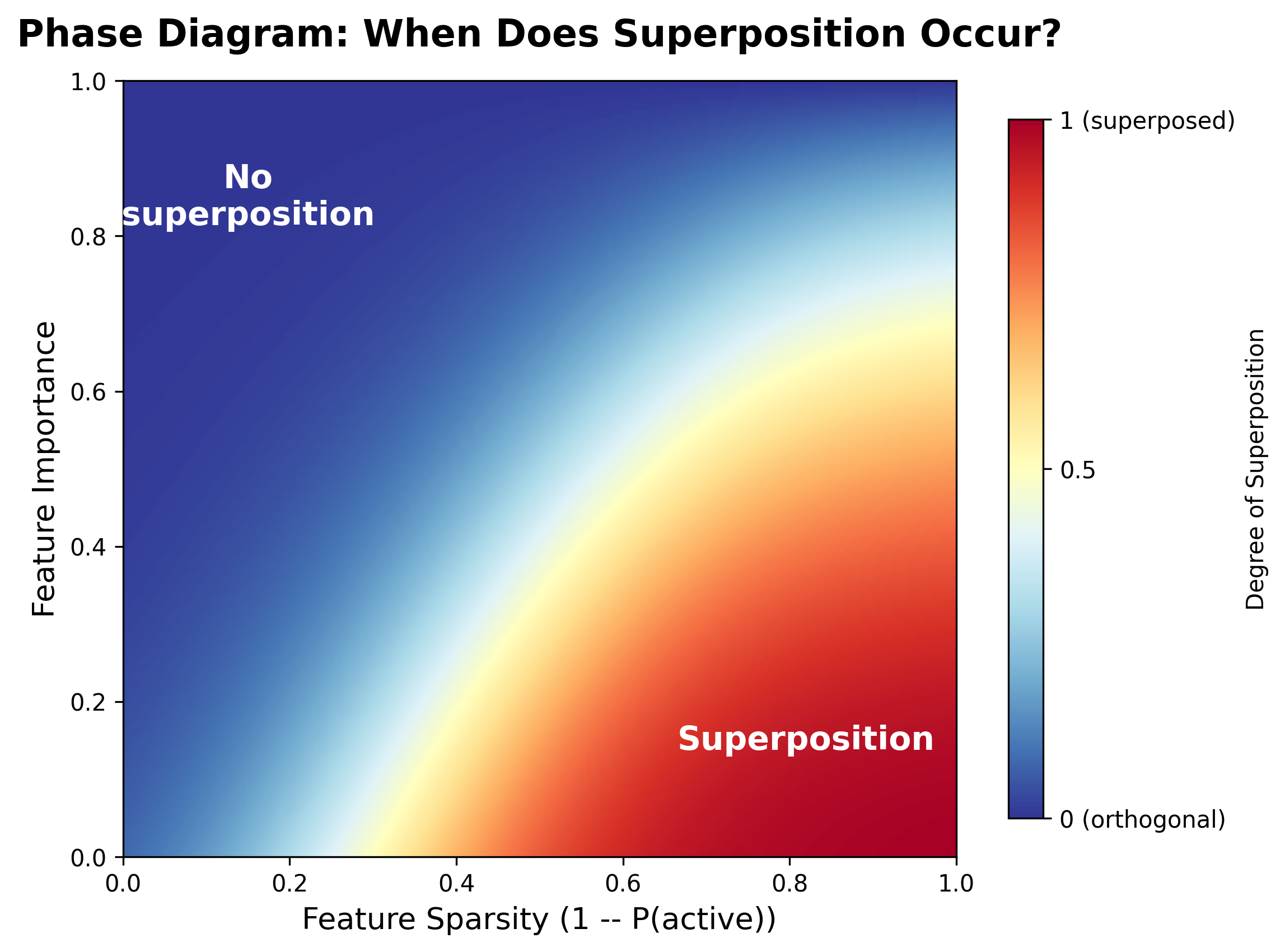
The phase diagram has two clear regions. The blue region (high importance, low sparsity) shows no superposition -- features get their own orthogonal dimensions. The red region (low importance, high sparsity) shows strong superposition -- features are packed into shared dimensions. The transition between regions is sharp, like a phase transition in physics.
Why does importance matter? High-importance features are too costly to represent with interference. If a feature matters a lot for the loss, any noise from interference is expensive, so the model dedicates a full orthogonal dimension to it. Low-importance features are cheap to represent noisily -- the model can tolerate interference because the cost of errors on these features is small.
Why does sparsity matter? This is the key insight that makes superposition work. If two features are both dense (frequently active), they interfere constantly. The cost of superposition is high. But if two features are sparse (rarely active), they rarely co-occur. Interference happens only when both are active simultaneously:
When both features are active only 1% of the time, interference occurs only 0.01% of the time. The probability of collision drops quadratically with sparsity.
Superposition is cheap when features are sparse. That is why it occurs: the model gets to represent more features at almost no cost.
The transition between "no superposition" and "superposition" is not gradual. As sparsity increases past a critical threshold, the model abruptly switches from orthogonal representation to superposed representation. This is reminiscent of phase transitions in physics -- ice melting to water at 0 degrees Celsius, or a magnet losing its magnetization above the Curie temperature. Below the threshold, features are orthogonal. Above it, they are packed. The threshold depends on feature importance: less important features transition at lower sparsity.
What does this mean for real language models? Most features in real models are sparse -- individual words, syntactic patterns, and factual associations are active on only a small fraction of inputs. Most features are not critically important -- only a few features (like "is this the end of a sentence?") matter for every prediction. This means most features in real models are in the red zone: low importance, high sparsity. The prediction is clear: real language models use superposition extensively.
The Geometry of Superposition
In the toy model, each feature is represented by a direction in the -dimensional hidden space. The encoder maps feature to direction , and the decoder reads out feature by projecting onto . The geometry of superposition is the geometry of how these directions are arranged in space.
When (as many features as dimensions), each feature gets its own axis. The directions are orthogonal: for . No interference -- activating feature has zero effect on the readout of feature . This is the ideal case.

When , you cannot fit orthogonal vectors in dimensions. The model must use non-orthogonal directions, and the angle between feature directions shrinks below 90 degrees. The interference between features and is proportional to their dot product: . Orthogonal features have zero interference; parallel features have maximal interference.
Pause and think: Optimal packing in 2D
Before looking at the specific arrangements the model discovers, think about this: if you had to place 3 unit vectors in a 2D plane to minimize the maximum dot product between any pair, where would you put them? What about 5 vectors? What about vectors in general?
The toy model discovers specific geometric arrangements that minimize interference, and these depend on the ratio . Let us walk through the progression.
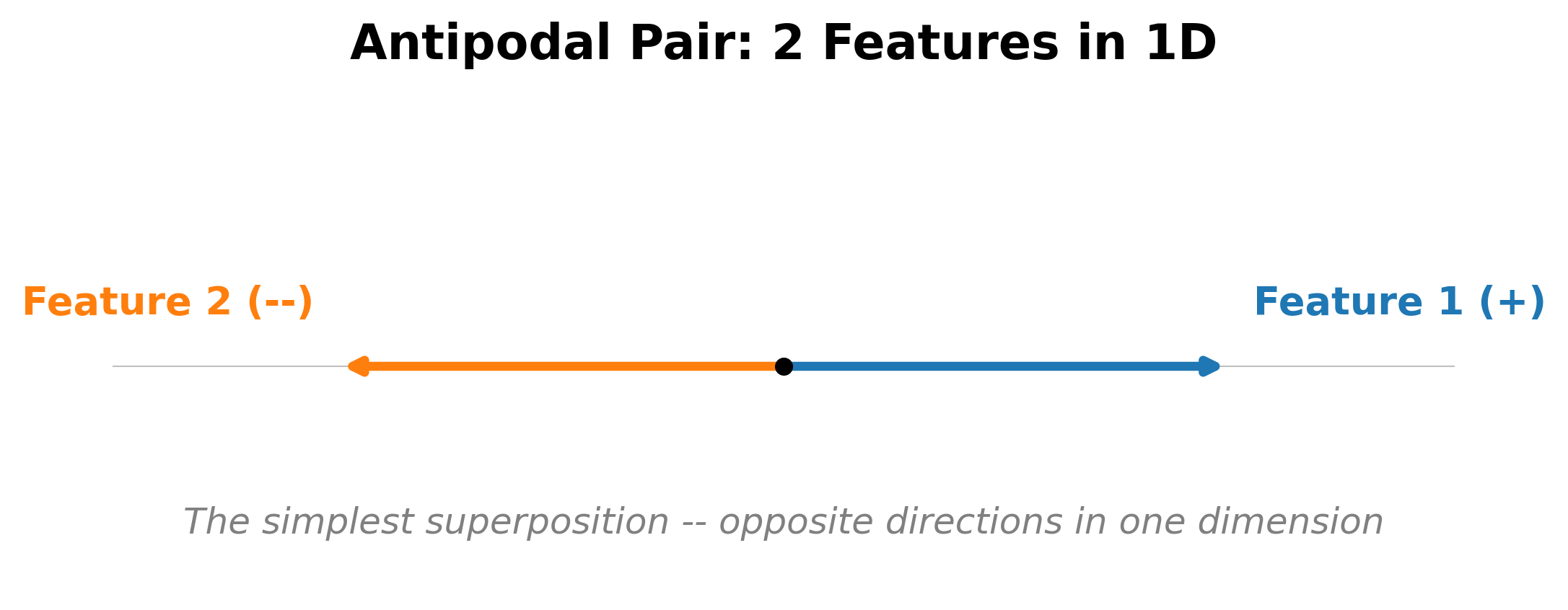
The simplest case of superposition is 2 features in 1 dimension. Feature 1 points right (+1) and feature 2 points left (-1). The dot product is , which is maximally interfering. But if both features are sparse, they rarely co-occur. When only one is active, the sign tells you which one. The gamble: with high sparsity, the "both active" case is rare enough that the model comes out ahead.
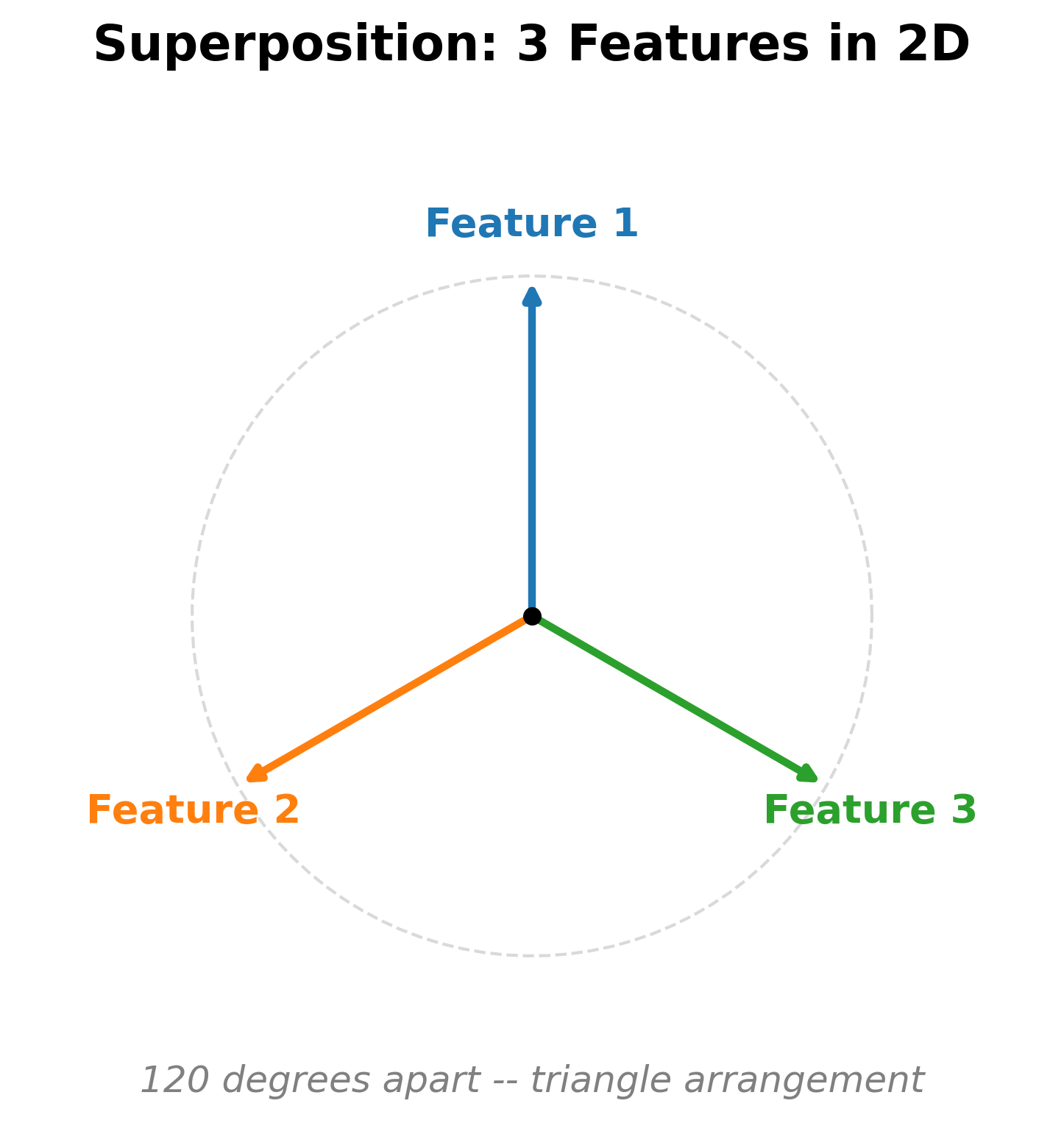
With 3 features in 2 dimensions, the model places three arrows at 120 degrees apart, forming a triangle. The dot product between any pair is -- moderate interference, but spread equally across all pairs. The triangle is the optimal packing of 3 unit vectors in 2D: it minimizes the maximum pairwise interference.
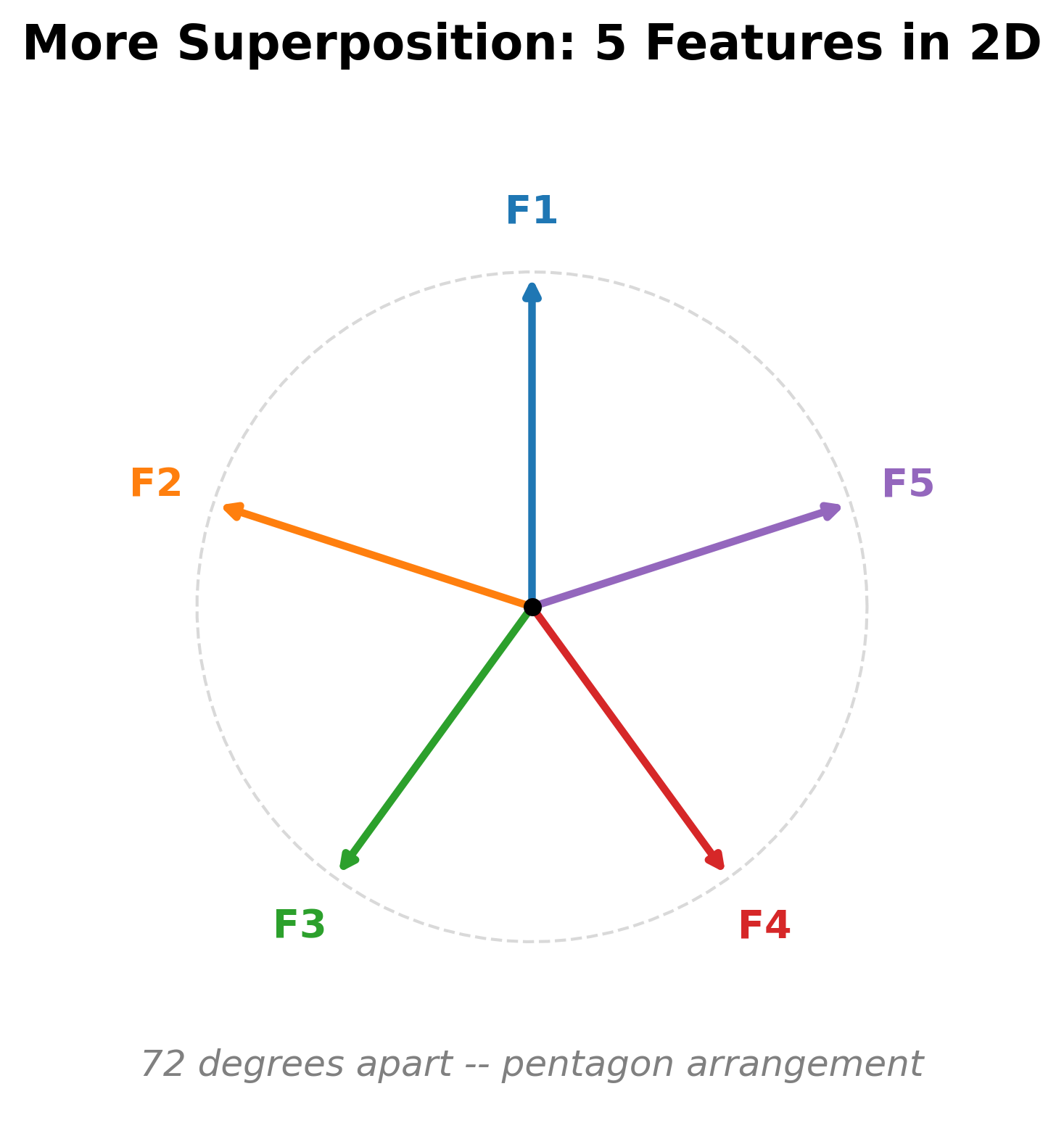
With 5 features in 2 dimensions, the model discovers the pentagon arrangement -- five arrows at 72 degrees apart. Adjacent features have , while non-adjacent features have . More features means some pairs are nearly anti-aligned. This arrangement works only for very sparse features where co-activation is exceedingly rare.
In three dimensions, the model packs 6 features as three antipodal pairs along the x, y, and z axes, forming an octahedron. Opposite features have dot product , while adjacent features have dot product . This combines antipodal pairing with orthogonality -- a remarkably efficient arrangement.

The pattern is striking. As we pack more features into a fixed number of dimensions, the optimal arrangements correspond to regular polytopes: the line segment in 1D, the triangle and pentagon in 2D, the octahedron and icosahedron in 3D, and more complex polytopes in higher dimensions.These optimal arrangements are exactly the shapes that maximize the minimum angle between any pair of directions. The model rediscovers classical results from sphere packing theory and the Tammes problem -- how to distribute points on a sphere to maximize the minimum distance between them. The connection to these well-studied mathematical problems is one of the most elegant findings of the toy model work. The model is not doing anything exotic. It is solving a well-known optimization problem: how to distribute directions as uniformly as possible.
The interference grows with packing density. At low packing ratios ( small), features are nearly orthogonal and readouts are clean. At high packing ratios ( large), features are far from orthogonal and readouts are noisy. The model chooses the packing density that optimizes the tradeoff between representing more features and suffering more interference.
Pause and think: Geometry at scale
The toy model with 5 features in 2D discovers the pentagon arrangement. In a real transformer with and potentially millions of features, what kind of geometric structure would you expect? Would the features form recognizable polytopes, or something less structured? Consider that in 768 dimensions, there is an enormous amount of room for nearly-orthogonal directions -- far more than our low-dimensional intuitions suggest.
Interference and Its Cost
When features are superposed, activating one feature partially activates others. Suppose features 1 and 2 have . When feature 1 is active with value , the readout of feature 2 picks up a ghost signal:
Feature 2 "sees" a ghost activation of 0.3 even though it is not active. This is interference, and it corrupts downstream computation in two ways. False positives occur when a feature appears active when it is not -- a ghost activation triggers behavior that should not have been triggered. Magnitude distortion occurs when a feature's true activation is shifted by interference from other active features, so even when a feature is correctly identified as active, its strength is wrong.
The expected cost of interference between features and depends on how often they are simultaneously active:
The geometric interference is fixed by the arrangement. But the effective cost is scaled by the co-occurrence probability. If , the effective cost is 10,000 times smaller than if both features are always active.This quadratic scaling with sparsity is what makes superposition so powerful. A 10x increase in sparsity does not just reduce interference 10x -- it reduces the expected interference cost 100x. This is why even moderate sparsity makes superposition overwhelmingly worthwhile for the model.
This is the superposition bargain. What the model gains: it represents features in dimensions, captures more structure in the data, and achieves lower loss on average. What the model pays: occasional interference when sparse features co-occur, noisy readouts for low-importance features, and activations that are harder to interpret. When features are sparse enough, the bargain is overwhelmingly favorable. The model gets to represent far more features at a cost that is negligible in expectation.
Why Superposition Makes Interpretability Hard
If features are superposed, individual neurons respond to multiple unrelated features. A single neuron might activate for "sports," "the color red," and "questions about geography" because these three features share that neuron's direction. This is polysemanticity: one neuron, many meanings. In a non-superposed model, each neuron would represent exactly one feature (monosemanticity). In a superposed model, neurons are mixtures.
The consequences for mechanistic interpretability are severe. Without superposition, we could interpret a model neuron by neuron: neuron 42 means "is a proper noun," neuron 43 means "is a verb," and so on. With superposition, neuron 42 might be , and neuron 43 might be . There is no clean interpretation of individual neurons. Features are directions in activation space, not neurons.
For circuit analysis, superposition means that the clean decompositions we found in earlier work become the exception rather than the rule. In a model with strong superposition, a single attention head might participate in five different circuits for five different tasks. The "Name Mover" feature might be distributed across twenty heads. Ablating one head disrupts all five circuits, not just the one we are studying. The confounds multiply.
Superposition creates a fundamental bottleneck for mechanistic interpretability. Neuron-level analysis fails because individual neurons are polysemantic mixtures, not clean features. Head-level analysis fails because individual heads participate in multiple circuits. Circuit discovery is harder because features overlap, making it difficult to isolate one circuit from another. Ablation experiments are confounded because ablating a component affects multiple features simultaneously.
How bad is it in practice? Evidence from real models suggests superposition is pervasive. Olah et al. (2020) documented polysemantic neurons in vision models -- neurons responding to cat faces and car hoods [4]Zoom In: An Introduction to Circuits
Olah, C., Cammarata, N., Schubert, L., et al.
Distill, 2020. Elhage et al. (2022) showed that even small toy models exhibit strong superposition when features are sparse [5]Toy Models of Superposition
Elhage, N., Hume, T., Olsson, C., et al.
Anthropic, 2022. Sparse probing experiments on production language models have added direct confirmation: some neurons are monosemantic (e.g., language-detection neurons that fire reliably for a single language), but the majority are polysemantic mixtures. The monosemantic neurons tend to correspond to high-importance, low-sparsity features -- exactly what the toy model predicts should escape superposition. Meanwhile, MLP layers appear to store factual associations in a superposed manner, with more facts than neurons and storage patterns that do not align with individual neuron axes. The vast majority of neurons in large language models do not have clean single-feature interpretations. Superposition is not an edge case. It is the default.
Superposition is the reason mechanistic interpretability is hard. Models represent more features than they have dimensions. Neurons are polysemantic. Circuits overlap. We need new tools.
One might hope that larger models (more dimensions) would reduce superposition. In part, yes: larger models can represent more features orthogonally. But larger models also learn more features. The number of useful features grows at least as fast as the model size, possibly faster. The ratio does not obviously shrink as models scale. Superposition may be a permanent feature of neural networks, not a problem that goes away with scale.
The natural question is: can we undo it? If features are encoded as directions in activation space, can we find those directions? Can we decompose a polysemantic neuron into its constituent monosemantic features? This is the decomposition problem, and the most promising current approach is sparse autoencoders (SAEs) -- separate networks trained to take a model's activations and decompose them into a sparse set of interpretable features. Whether SAEs deliver on this promise, and what their limitations are, is the subject of the next article.