From Superposition to Dictionary Learning
The superposition hypothesis established that neural networks encode more features than they have dimensions by packing features as nearly-orthogonal directions in activation space. The consequence is polysemanticity: individual neurons respond to multiple unrelated concepts, and the clean circuit decompositions we found in earlier work become the exception rather than the rule.
But the superposition hypothesis also suggests a path forward. If model activations are approximately sparse linear combinations of feature directions, then recovering those directions is a well-studied problem. Mathematically, if we assume activations take the form:
where is a sparse feature vector (most entries are zero) and is an overcomplete dictionary with more columns than the activation space has dimensions, then learning and recovering from observed activations is the dictionary learning problem. This is also a compressed sensing problem: recovering a high-dimensional sparse signal from low-dimensional observations.Dictionary learning and compressed sensing are well-established fields in signal processing and statistics. The key theoretical result is that if the feature vector is sufficiently sparse relative to the number of dimensions, the decomposition is unique. This is what makes recovery possible despite having more features than dimensions -- the same sparsity that enables superposition also enables its reversal.
Without sparsity, the problem would be hopeless. If all features in dimensions (with ) were simultaneously active, there would be infinitely many valid decompositions. But if is sparse -- only a few features active at any time -- the solution becomes unique. Sparsity is what makes superposition possible, and sparsity is what makes undoing superposition possible.
The key insight of Bricken et al. is to use a deliberately simple architecture for this dictionary learning -- a one-layer autoencoder rather than a more powerful algorithm [1]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Bricken, T., Templeton, A., Batson, J., et al.
Anthropic, 2023. Why? A too-powerful algorithm might recover features from activations that the model itself cannot access. The SAE architecture is deliberately similar to an MLP layer, ensuring that the recovered features are ones the model could plausibly use. This is "weak" dictionary learning on purpose: we want features that are accessible to the model, not just features that exist in the data.
Pause and think: Why weak dictionary learning?
If a powerful feature extraction method recovers features that the model cannot compute, are those features real representations of the model, or artifacts of the extraction method? Consider what it would mean to find a feature that is statistically present in the activations but that no computation in the model ever reads or writes. Would interpreting the model through that feature give accurate causal explanations?
The SAE Architecture
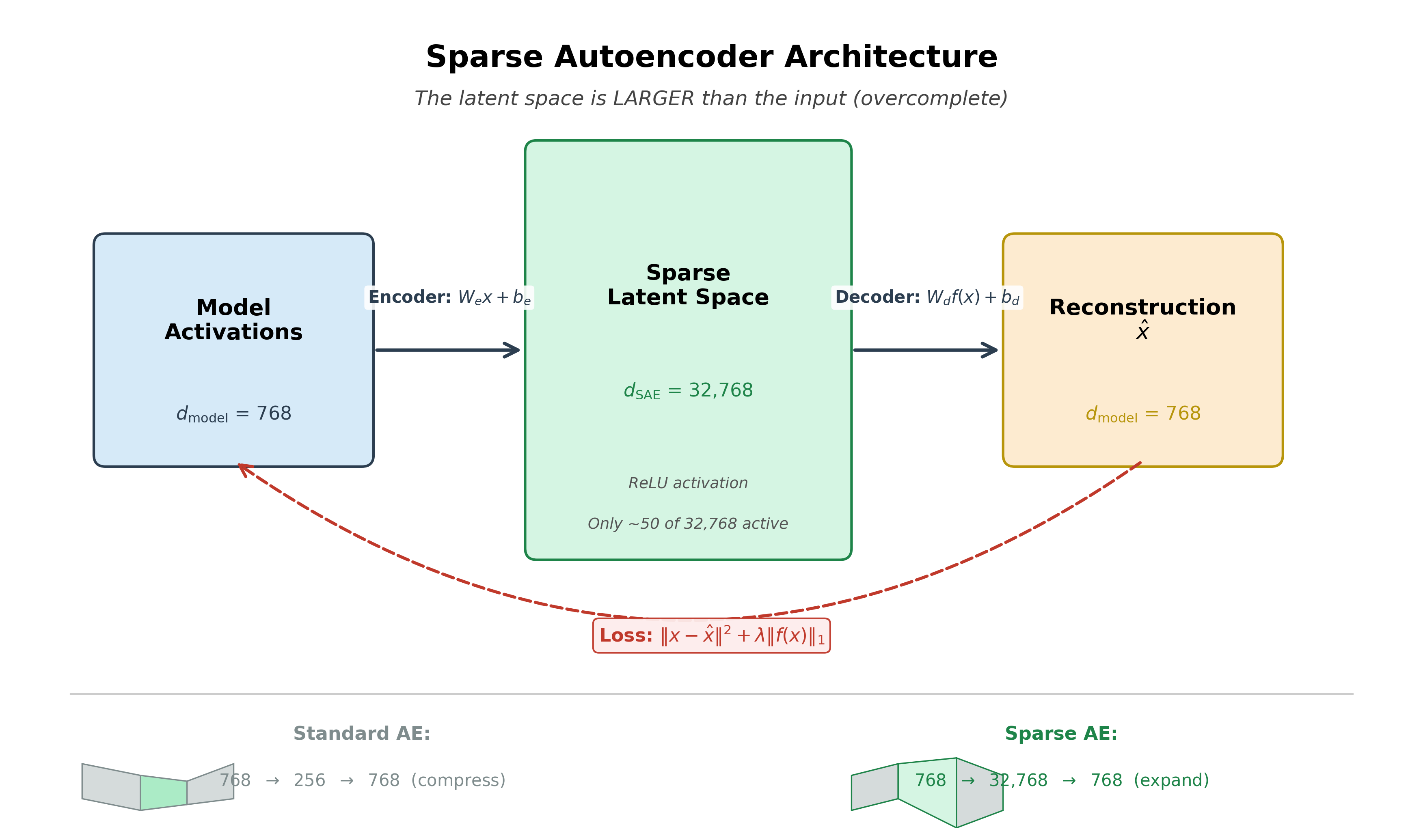
A sparse autoencoder has three components: an encoder that projects activations into a wider latent space, a ReLU nonlinearity that enforces sparsity, and a decoder that reconstructs the original activations.
Sparse Autoencoder (SAE): A neural network with an overcomplete latent space (more latent dimensions than input dimensions) trained with a sparsity penalty. It decomposes model activations into sparse combinations of interpretable features. The encoder maps dimensions to dimensions (with ), and the decoder maps back.
The encoder projects activations from the model's dimensionality to a much larger latent space, then applies ReLU to enforce non-negativity:
where and . Typical expansion factors range from 4x to 256x. A model with 768 dimensions might use a latent space of 32,768 dimensions. The ReLU ensures that latent activations are non-negative, and most are zero -- producing the sparsity we need.
The decoder projects the sparse latent representation back to the model's dimensionality:
where . Each column of is a feature direction in the activation space. When a latent dimension is active, the corresponding column contributes to the reconstruction. The decoder learns the dictionary of features.This is the opposite of a standard autoencoder. A standard autoencoder compresses: 768-dimensional input becomes a 256-dimensional latent representation, then is reconstructed back to 768 dimensions. The purpose is dimensionality reduction. An SAE expands: 768-dimensional input becomes a 32,768-dimensional latent representation. The purpose is not compression but decomposition -- finding many individual features that combine to form the input. The sparsity constraint ensures that only a few of those 32,768 dimensions are active for any given input.
The loss function combines two objectives that pull in opposite directions:
The reconstruction term ensures the SAE faithfully represents the input -- if it discards too much information, this term grows large. The L1 sparsity term penalizes the total magnitude of latent activations, pushing most of them toward zero. The coefficient controls the tradeoff: higher produces sparser features (fewer active per input, cleaner interpretations) but worse reconstruction (more information lost). Lower gives better reconstruction but features may remain polysemantic.
Finding the right is a key practical challenge. Too much sparsity means the SAE loses important information -- features are clean but the reconstruction is poor, and some real features are never discovered. Too little sparsity means the reconstruction is good but individual latent dimensions blend multiple concepts, defeating the purpose of decomposition.
Training SAEs
SAEs are trained on model activations, not raw text. The process works as follows:
- Run the target model on a large corpus of text.
- Collect the activations at a chosen site (for example, the residual stream at layer 6) for every token.
- Use these collected activations as training data for the SAE.
The SAE never sees the original text directly. It operates entirely in activation space. For each batch of activations, the training loop encodes them to the overcomplete latent space, applies ReLU, decodes back, computes the combined reconstruction and sparsity loss, and updates the SAE weights via gradient descent. The original model's weights remain frozen throughout -- the SAE is a separate decomposition tool, not a modification of how the model computes.Think of the SAE as a microscope: it reveals structure in the activations without changing what the model does. The SAE's encoder learns to detect which features are present in a given activation vector, and its decoder learns the direction in activation space that each feature corresponds to. But the model itself is unchanged.
Several design decisions affect what the SAE discovers:
- Expansion factor: How many latent dimensions relative to the input. Larger expansion means more potential features but also more dead features (latent dimensions that never activate) and higher compute cost.
- Where to apply the SAE: The residual stream is the most common choice, capturing the cumulative representation at a given layer. MLP outputs tend to capture features related to factual knowledge and associations. Attention outputs capture features related to syntactic patterns and information routing.
- Training data volume: Bricken et al. trained on 8 billion activations [2]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Bricken, T., Templeton, A., Batson, J., et al.
Anthropic, 2023. Rare features (such as legal citations or DNA sequences) require enormous numbers of tokens before they appear in enough training examples.
Pause and think: Standard autoencoders vs. sparse autoencoders
A standard autoencoder compresses a 768-dimensional input into a 256-dimensional latent space and reconstructs back to 768 dimensions. An SAE expands a 768-dimensional input into a 32,768-dimensional latent space and reconstructs back to 768 dimensions. Both minimize reconstruction error.
Why does the SAE need a sparsity penalty while the standard autoencoder does not? What would happen if you trained an SAE without the L1 term? Consider what constraint forces a standard autoencoder to learn useful structure (the bottleneck), and what plays the analogous role in an SAE.
Towards Monosemanticity: Results
Bricken et al. applied their SAE to a one-layer transformer with a 512-neuron MLP layer [3]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Bricken, T., Templeton, A., Batson, J., et al.
Anthropic, 2023. The SAE had a 16x expansion factor: 512 MLP neurons became 8,192 latent dimensions. Trained on 8 billion activations collected from the model processing diverse text, the central question was straightforward: can the SAE decompose 512 polysemantic neurons into clean, monosemantic features?
The result was striking:
Each feature corresponds to a distinct concept. The features are monosemantic: each one fires on one type of content and is quiet on unrelated content. Examples include features for Arabic script, DNA sequences, legal language, HTTP requests, Hebrew text, and nutrition statements. This is 8x more features than neurons. Where were these features hiding? In superposition. The 512 neurons were collectively encoding thousands of overlapping features as nearly-orthogonal directions in activation space.
Human raters evaluated a large random sample and found approximately 70% of SAE features to be genuinely interpretable -- dramatically better than neuron-level analysis, where most neurons respond to seemingly unrelated inputs and resist clean interpretation [4]Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Bricken, T., Templeton, A., Batson, J., et al.
Anthropic, 2023. Not all features are perfectly clean. Some remain somewhat polysemantic, especially when the SAE is too small. Larger SAEs with more features tend to produce cleaner decompositions.Concurrent work by Cunningham et al. (2023) independently demonstrated that SAEs find interpretable features in language models, published at ICLR 2024. This independent replication was important: it showed that the approach works across different research groups and model families, not just in one specific setup. The convergence of independent findings substantially strengthened the case that SAEs reveal real structure rather than artifacts of a particular training procedure.
Bricken et al. provided four distinct lines of evidence for the quality of their features:
- Detailed case studies: In-depth investigation of specific features, constructing computational proxies to verify their function.
- Human evaluation: Raters assessed a large random sample, finding the 70% interpretability rate described above.
- Automated interpretability (activations): LLMs generated descriptions from activation patterns, then tested those descriptions on held-out data.
- Automated interpretability (logit weights): Analysis of how features influence the model's output distribution.
The combination of targeted manual analysis and broad automated evaluation gives the most reliable picture of feature quality. Detailed case studies verify that individual features are real. Human evaluation provides an overall quality estimate. Automated methods enable scaling evaluation to thousands of features.
The results demonstrate that the SAE successfully reverses superposition -- at least for a small model. The 512 polysemantic neurons were decomposed into thousands of monosemantic features, each representing a coherent concept. This is the first tool that directly addresses the superposition problem.
For how researchers inspect and interpret the features SAEs discover, including the feature dashboard methodology and automated interpretability at scale, see the next article on feature dashboards and automated interpretability. For the question of whether this approach scales to production-size models, see scaling monosemanticity.