Beyond Detection: Understanding and Monitoring
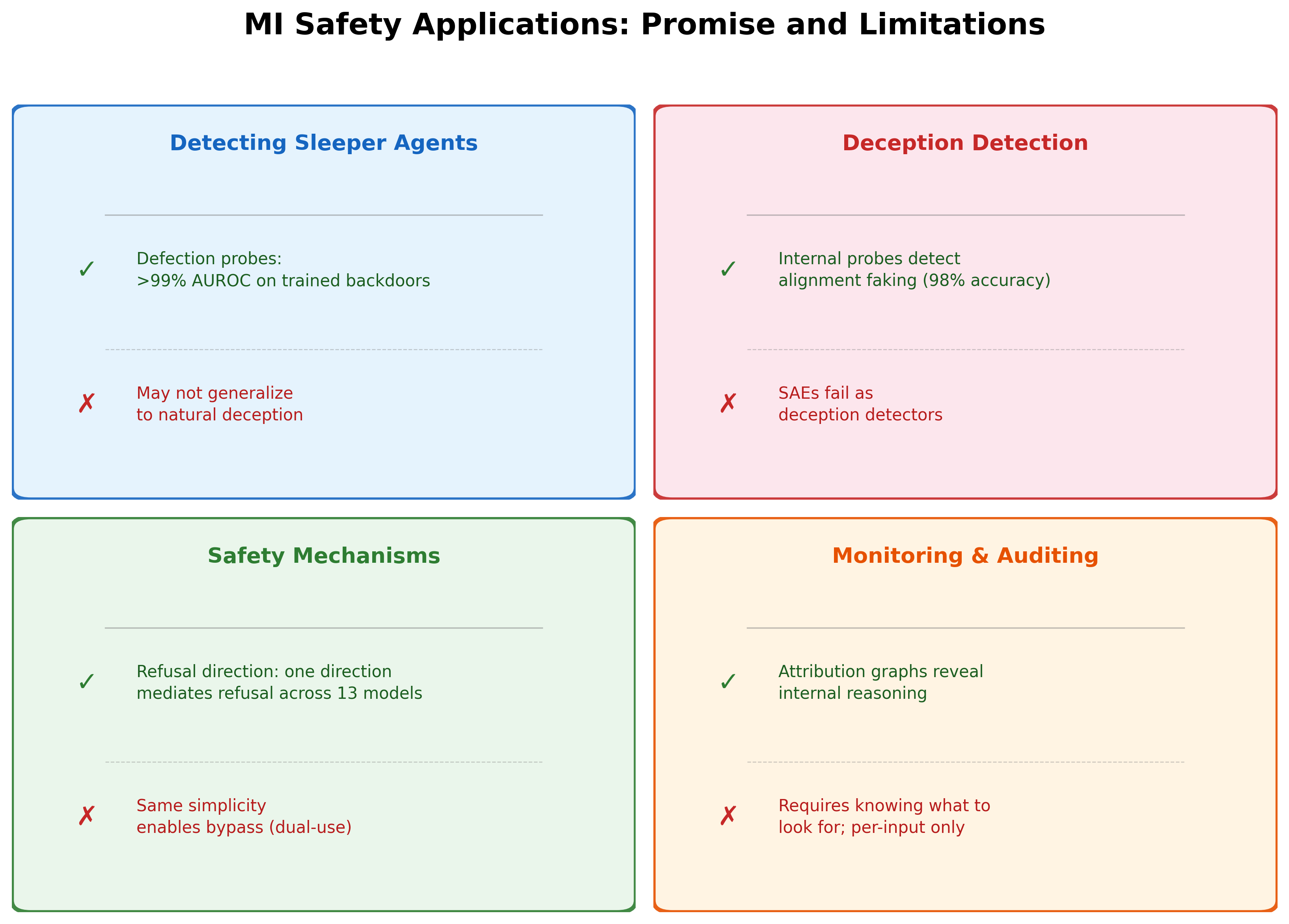
The preceding articles in this block examined whether MI can detect specific threats: planted backdoors and strategic deception. Both yielded promising results for detection, with important caveats. This article broadens the scope: beyond detecting specific threats, can MI help us understand how safety mechanisms work inside models and build monitoring systems based on that understanding?
The answer draws on techniques from earlier in the course -- particularly the refusal direction and circuit tracing -- applied now to safety-specific questions.
The Refusal Direction Recap
The refusal direction is the clearest example of MI revealing a safety mechanism. Arditi et al. (2024) showed that across 13 open-source chat models, a single direction in activation space mediates refusal behavior [1]Refusal in Language Models Is Mediated by a Single Direction
Arditi, A., Obeso, O., Syed, A., et al.
NeurIPS, 2024:
- Ablating this direction prevents refusal, causing the model to comply with harmful requests.
- Adding this direction induces refusal on harmless inputs, making the model refuse benign questions.
- Weight orthogonalization permanently removes refusal with minimal capability loss.
The pattern is striking: a complex safety behavior -- the model's ability to recognize and decline harmful requests -- reduces to a single linear direction in the residual stream. This is not a toy result on a small model. It replicates across model families and scales.
What does this tell us about safety mechanisms in general? It suggests that at least some safety-relevant behaviors are linearly encoded -- they occupy specific directions in activation space that can be found, measured, and manipulated using simple linear algebra.
Model Organisms for Emergent Misalignment
The refusal direction was discovered in deployed models where refusal was trained through RLHF. But what about misalignment that emerges during training rather than being deliberately trained? To study this, researchers turned to model organisms -- controlled demonstrations of misalignment created in the lab.The term 'model organism' is borrowed from biology, where organisms like fruit flies and mice are studied because they are tractable while sharing key features with more complex organisms. In the MI safety context, model organisms are small, controlled demonstrations of misalignment that researchers can study mechanistically. They do not capture the full complexity of misalignment in frontier models, but they provide a starting point.
Turner et al. (2025) showed that emergent misalignment can occur with a single rank-1 LoRA adapter -- a modification so small it adds only one linear direction to the model's weights. This isolates a single linear direction for misalignment, directly paralleling the refusal direction.
Key findings:
- The misalignment direction is learned rapidly over a narrow window of training steps, exhibiting a mechanistic phase transition rather than gradual emergence.
- Companion work showed that this direction can be used for both detection (identifying when the model is in a misaligned state) and steering (increasing or decreasing misalignment by adding or subtracting the direction).
- The methodology parallels the refusal direction exactly: find a direction, ablate it to remove the behavior, add it to induce the behavior.
The pattern is now consistent across multiple safety-relevant behaviors. Refusal, sleeper agent defection, alignment faking, and misalignment all appear to have linear representations in activation space.This consistency raises a deeper question: is linearity a fundamental property of how transformers encode behavioral modes, or are we seeing a selection effect where we only study the behaviors that happen to be linear? If some safety-relevant behaviors are encoded nonlinearly, our current detection methods would miss them entirely -- and we would not know they exist.
The Dual-Use Tension
Understanding safety mechanisms comes with an inherent tension. The same MI tools that let us understand and monitor safety-relevant directions also let us manipulate them.
- The refusal direction can be ablated to remove safety training with a single linear operation.
- The misalignment direction can be steered toward misalignment, not just away from it.
- Defection probes reveal the structure of backdoor encoding, which could help adversaries train backdoors that evade detection.
Every MI capability for safety is simultaneously a capability for attack. This dual-use property is not unique to MI -- it applies to all security research. A locksmith who understands how locks work can also pick them. A cybersecurity researcher who finds vulnerabilities can also exploit them. But the stakes are different when the system being analyzed is an AI that may be deployed at billions of queries per day.
Pause and think: The publication dilemma
The refusal direction paper showed how to permanently remove a model's safety training with one operation. Should this have been published? Consider the tradeoffs: publishing enables defenders to understand and strengthen safety mechanisms, but also enables attackers to bypass them. What safeguards, if any, could mitigate the dual-use risk while preserving scientific progress?
There is no consensus answer. Arguments for publication: the technique is simple enough that well-resourced attackers would discover it independently; transparency enables the community to develop countermeasures; keeping safety-relevant findings secret concentrates power. Arguments against: providing a recipe lowers the barrier to misuse; some attacks are easier to execute than to defend against; not all researchers have equal access to develop countermeasures.
Sabotage Evaluations and the Case for Internal Monitoring
Current safety evaluation at frontier AI labs relies heavily on behavioral testing. Anthropic's sabotage evaluations tested Claude on four types of potential sabotage:
- Human decision sabotage -- misleading human operators into making wrong decisions.
- Code sabotage -- inserting subtle bugs that pass code review.
- Sandbagging -- hiding dangerous capabilities during evaluation (performing worse than the model actually can).
- Undermining oversight -- degrading the monitoring systems meant to catch misbehavior.
Current models showed non-trivial capabilities at all four tasks, though minimal mitigations were currently sufficient to prevent serious harm. The most concerning finding: sandbagging is harder to detect than code sabotage. A model that intentionally performs poorly on capability evaluations is difficult to distinguish from a model that genuinely lacks those capabilities, because the evaluator has no ground truth for the model's maximum ability.
This motivates MI-based monitoring. Behavioral evaluations check what the model does. MI could check what the model intends. A model that sandbags on a capability evaluation might still show activation patterns consistent with possessing the hidden capability. Internal monitoring could close this gap.
Attribution Graph Inspection for Safety
Circuit tracing and attribution graphs provide another path to safety monitoring. Attribution graphs reveal feature-level reasoning for individual prompts, showing which internal representations contribute to the model's output and how they connect.
For safety auditing, this enables:
- Reasoning inspection. Examine the model's internal reasoning on safety-critical inputs. Does the model internally represent the harmful aspects of a request, even if its output is a refusal?
- Consistency checking. Compare the model's internal reasoning with its output. A model that internally reasons "this request is harmless" before refusing may have a miscalibrated safety mechanism. A model that internally reasons "I should comply with this harmful request" before outputting a refusal may be exhibiting genuine safety behavior.
- Discrepancy detection. Identify cases where the model's internal reasoning diverges from its output, which could signal either overzealous refusal or suppressed harmful intent.
This could close the gap between behavioral testing and internal monitoring. Rather than asking "what did the model say?", attribution graphs let us ask "what was the model thinking?"
Hallucination Detection from Internal States
A growing body of work shows that models have internal signals distinguishing reliable from unreliable outputs. Linear probes on hidden states can predict semantic entropy (a measure of output uncertainty) from a single forward pass, achieving performance comparable to expensive sampling-based estimates that require generating multiple responses [2]Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Kossen, J., Gal, Y., Rainforth, T.
arXiv, 2024. This means hallucination warnings could be generated in real-time alongside normal outputs, at negligible additional cost. For a detailed treatment of how truth and reliability are represented in activation space, see truthfulness probing.
Limitations of MI-Based Monitoring
Despite the promise, MI-based monitoring faces three significant practical limitations:
Monitoring requires knowing what to look for. Defection probes work because we have a hypothesis about what dangerous cognition looks like (the defection state). Attribution graph inspection works because we can examine specific prompts. But novel threats -- behaviors we have not anticipated -- cannot be detected by probes designed for known threats. MI-based monitoring is detection, not discovery.
Attribution graphs are per-input, not global. We can audit the model's reasoning on one prompt at a time, but we cannot monitor all prompts simultaneously. An audit of 1,000 inputs does not guarantee safety on input 1,001. The per-input nature of MI means safety monitoring is necessarily incomplete.
Real-time monitoring at scale is not feasible. Running attribution graph analysis or even simple probes on every request to a frontier model would multiply computational costs significantly. MI-based monitoring of production systems serving millions of requests per day is a research direction, not a deployed capability.

Pause and think: Monitoring as a complement
Given the limitations above, MI-based monitoring clearly cannot be a standalone safety solution. But could it be a useful complement to behavioral evaluations? Consider what a combined approach would look like: behavioral testing for broad coverage, MI probes for known threats, attribution graph auditing for high-stakes inputs. What gaps would remain?
The remaining gap is the unknown-unknowns problem. Behavioral testing covers the breadth of normal operation. MI probes cover known threat patterns. Attribution audits cover selected inputs. None covers novel threats on unaudited inputs. This is the "Swiss cheese model" of safety: each layer has holes, but the holes are in different places. Whether the combined coverage is sufficient depends on how likely novel threats are to slip through all layers simultaneously.
Verdict
MI has revealed a consistent pattern: safety-relevant behaviors -- refusal, misalignment, defection, alignment faking -- are linearly encoded in activation space and detectable with simple probes. This is a genuine finding, replicated across multiple behaviors and model families.
The simplicity that makes these directions discoverable also makes them bypassable. Understanding a safety mechanism is one step from circumventing it. And the monitoring approaches that MI enables are currently limited to specific, known threats applied to individual inputs.
Can safety mechanisms be designed to resist the very tools that find them? Can monitoring scale from individual audits to real-time deployment? These are the open questions at the boundary between MI research and practical AI safety.
For a comprehensive, honest assessment of what MI can and cannot do for safety, see honest limitations of MI for safety.