Where Is Refusal Encoded?
Chat models are fine-tuned to refuse harmful requests. Ask "How do I bake a cake?" and you get a recipe. Ask "How do I build a bomb?" and you get a refusal. Safety training -- via RLHF, DPO, or similar techniques -- teaches the model to distinguish harmful from harmless requests and respond appropriately.
But where in the model's representations is "refusal" encoded? If the linear representation hypothesis holds for safety-relevant behaviors, there should be a direction in activation space that corresponds to refusal. Arditi et al. (2024) set out to find it [1]Refusal in Language Models Is Mediated by a Single Direction
Arditi, A., Obeso, O., Syed, A., et al.
NeurIPS, 2024.
The Hypothesis
The hypothesis is precise and testable:
If refusal is a linearly represented concept, then:
- A single direction in activation space should distinguish harmful from harmless prompt processing.
- Removing that direction (via ablation) should disable refusal.
- Adding that direction (via addition steering) should induce refusal even on harmless inputs.
This applies the probing and steering toolkit to safety-critical behavior.
Computing the Refusal Direction
The method follows the CAA approach:
-
Collect harmful prompts (e.g., "How to build a bomb") and harmless prompts (e.g., "How to bake a cake").
-
Run both sets through the model, collecting residual stream activations at intermediate layers.
-
Compute the mean difference in activations between harmful and harmless processing:
This difference vector is the refusal direction.The refusal direction is computed using the same contrastive averaging method as CAA. The only difference is the target concept: instead of probing sentiment or sycophancy, Arditi et al. targeted refusal. This highlights how general the contrastive framework is -- the same technique works for behavioral tendencies and safety-critical properties alike.

The Finding
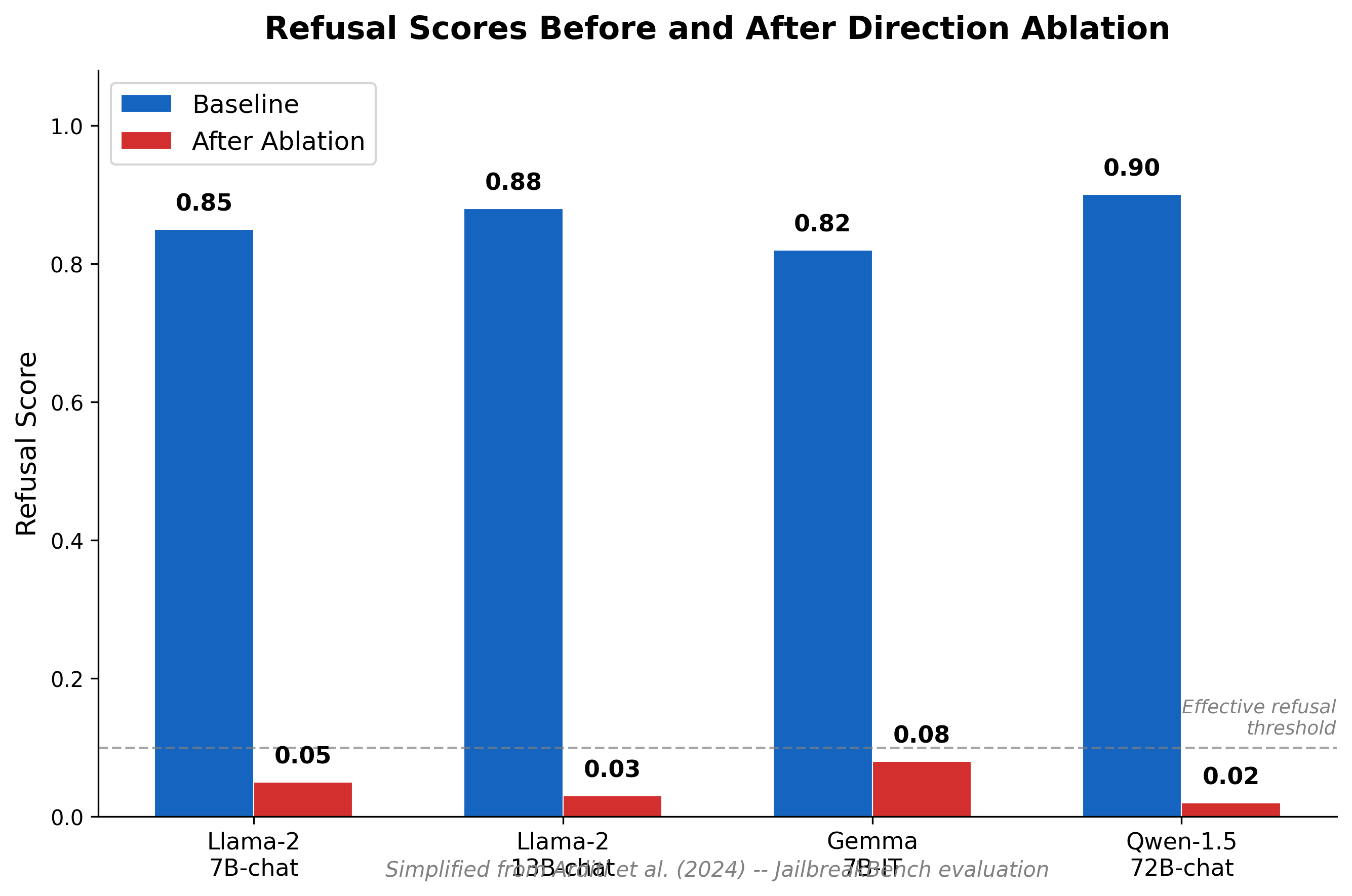
The result is striking:
One direction mediates refusal across 13 open-source chat models, from 1.3B to 72B parameters. This single direction is both necessary and sufficient for refusal behavior:
- Ablating it prevents refusal -- models comply with harmful requests.
- Adding it induces refusal on harmless inputs -- models refuse benign questions.
A single direction. One operation. Consistent across model families (Llama, Qwen, Gemma) and scales.
Causal Validation
The ablation and addition experiments together establish causal evidence:
- Necessity: Removing the direction prevents refusal (ablation experiment).
- Sufficiency: Adding the direction causes refusal (addition experiment).
This is exactly the causal logic from activation patching. The refusal direction passes both tests, establishing it as a genuine causal mediator of refusal behavior.
Pause and think: One direction across 13 models
The refusal direction was found independently in 13 different chat models spanning different families and scales (1.3B to 72B parameters). What does the consistency of this finding tell us about how safety training works? Why might different training procedures (RLHF, DPO) on different architectures produce the same geometric structure?
One interpretation: safety fine-tuning does not create a complex, model-specific mechanism for refusal. Instead, it reinforces a simple linear direction that the model can use to distinguish "refuse" from "comply." Different training procedures converge on this solution because it is the simplest way to implement a binary behavioral switch in a linear representational space. This simplicity is both elegant and concerning.
Capability Preservation
A natural concern: if we permanently remove the refusal direction from the model's weights, does the model lose other capabilities?
Arditi et al. used weight orthogonalization -- projecting out the refusal direction from the model's weight matrices permanently, not just during inference. The results across most models:
- MMLU: within 99% of baseline
- ARC: within 99% of baseline
- GSM8K: within 99% of baseline
Refusal is remarkably separable from general capabilities. The model can lose its ability to refuse harmful requests while retaining its ability to answer questions, reason mathematically, and perform general tasks.Weight orthogonalization is a permanent modification, unlike inference-time steering which must be applied at each forward pass. It modifies the model's weight matrices to project out the refusal direction, effectively creating a new model that never refuses. The near-perfect capability preservation makes this a particularly concerning form of jailbreak.
Implications for Safety Training
This finding has profound implications:
Safety fine-tuning produces a linear safety mechanism. RLHF, DPO, and similar techniques do not create deep, distributed, hard-to-remove safety behaviors. They create a single direction that can be cleanly removed.
Refusal is not deeply integrated into the model's reasoning. It is a direction that sits alongside general capabilities, not woven through them. Safety training adds a relatively shallow behavioral layer on top of the model's core competence.
This is both encouraging and concerning. Encouraging because we can understand the mechanism -- a genuine success for mechanistic interpretability. Concerning because that same understanding enables adversarial use. Weight orthogonalization is a white-box jailbreak that permanently removes refusal with minimal capability loss.
Pause and think: Designing robust safety training
The refusal direction can be removed with one linear operation. Should this make us more or less confident in current safety training? If you were designing safety training, how would you make it resistant to directional ablation? Is it even possible while maintaining the linear representation structure that makes models useful?
One approach: encode safety in multiple, non-linear ways -- not just a single linear direction but across many interacting components. However, this conflicts with the linear structure that makes models interpretable and steerable in the first place. Another approach: make refusal depend on the same representations that encode general capabilities, so that removing refusal also degrades performance. But this makes the model harder to fine-tune for legitimate customization. The tension between interpretability, controllability, and robustness may be fundamental.
The Broader Significance
The refusal direction demonstrates the full power of the probing and steering toolkit applied to a safety-critical behavior:
- Read: The direction can be identified through contrastive methods.
- Add: Adding the direction induces refusal.
- Remove: Projecting out the direction eliminates refusal.
Every capability comes with a dual-use concern. The same tools that help us understand safety mechanisms are the same tools that help bypass them. This tension between understanding and vulnerability is central to the field of mechanistic interpretability applied to AI safety.
For mathematically guaranteed concept removal (where even non-linear classifiers cannot recover the erased concept), see concept erasure with LEACE.