Attention Pattern Visualization
The most intuitive observational tool is to look at where attention heads direct their focus. Attention patterns show us which positions each token attends to, revealing structural patterns that provide clues about head function.
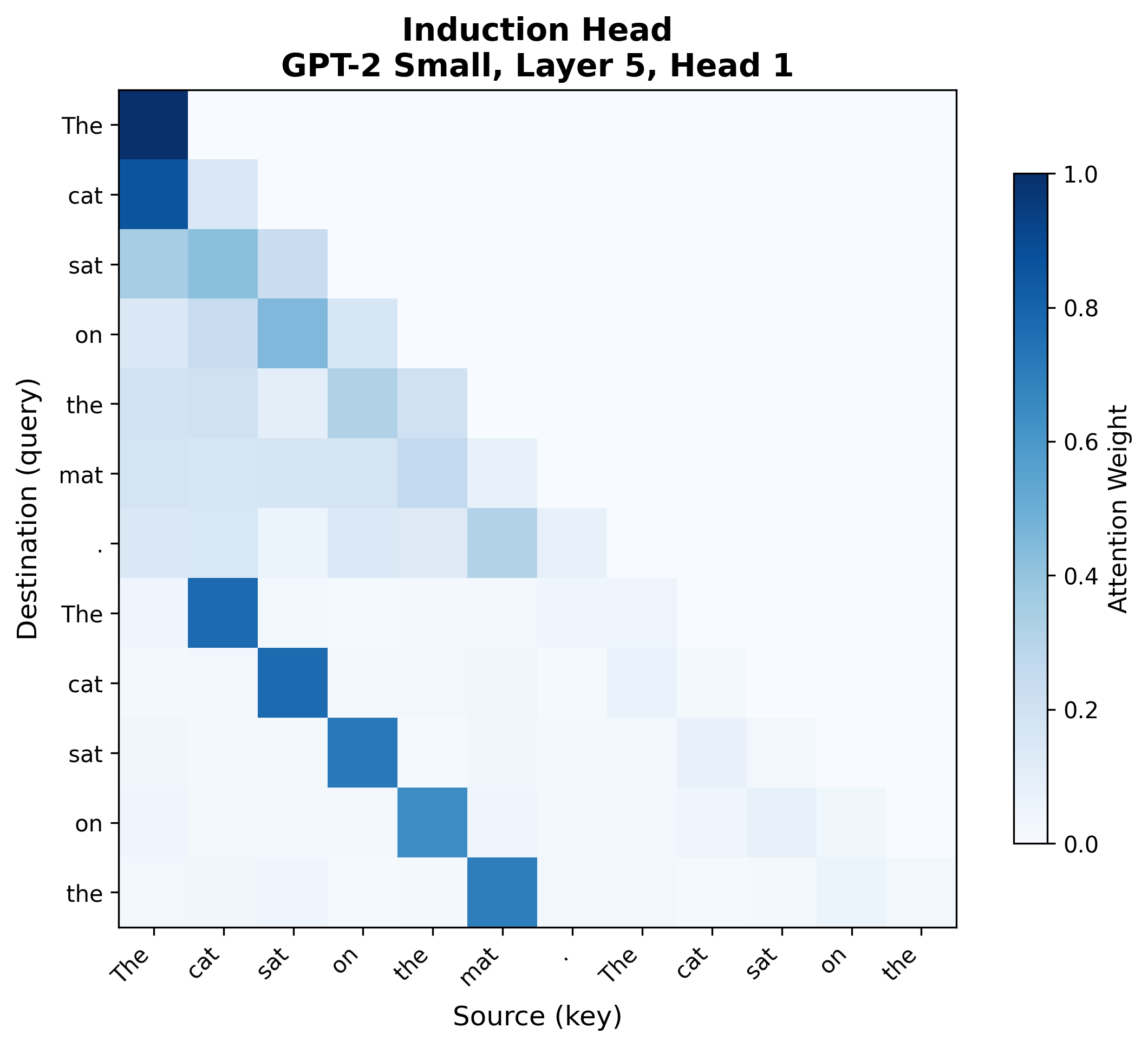
Consider GPT-2 Small processing a repeated sequence: "The cat sat on the mat. The cat sat on the." Two heads display distinctive patterns:
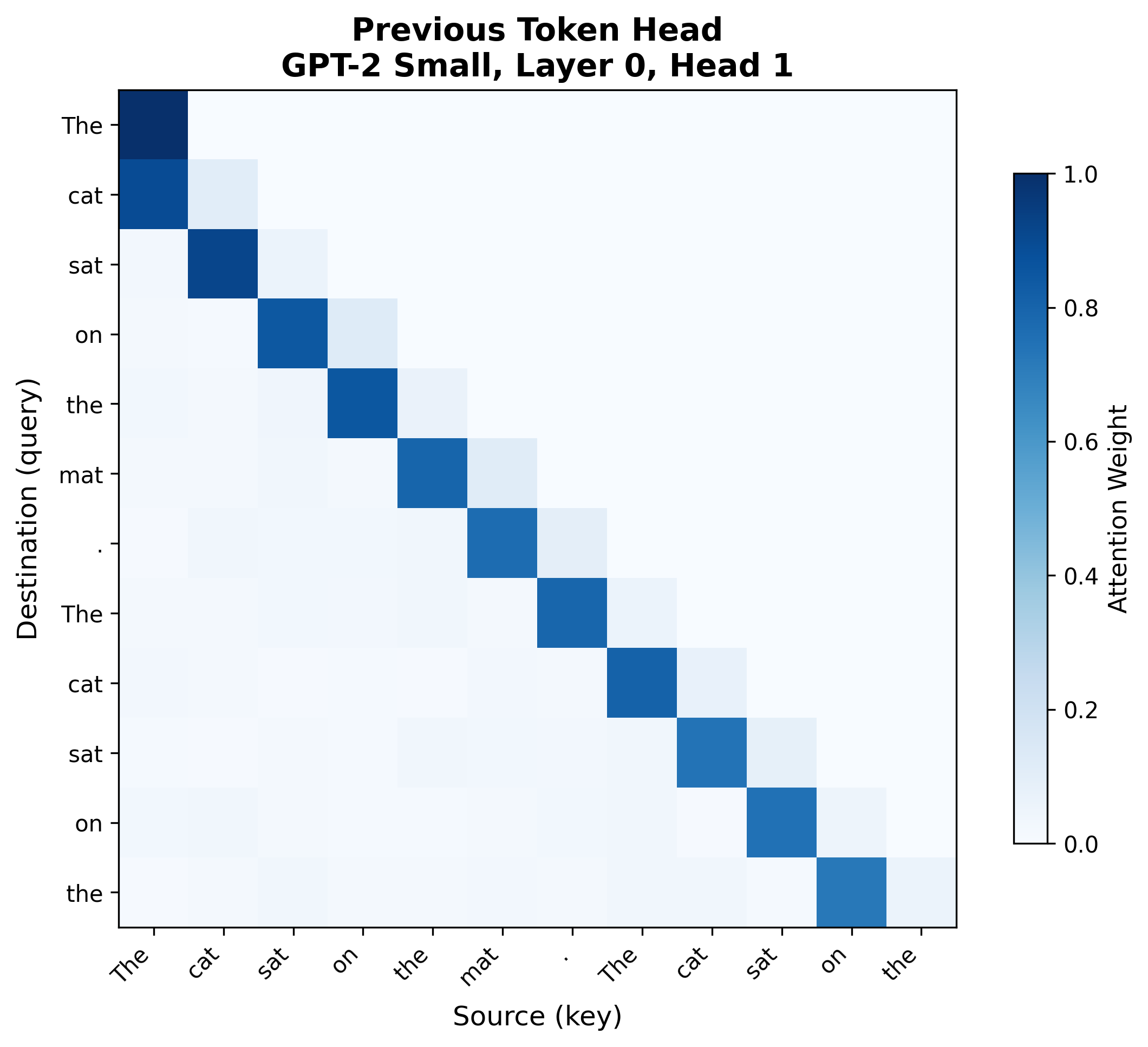
The first pattern is a previous token head (Layer 0, Head 1): a clean diagonal where each position attends to the position immediately before it. This head implements the first step of the induction circuit, writing "my predecessor was token X" into each position's residual stream.
The second pattern is an induction head (Layer 5, Head 1): in the second half of the repeated sequence, attention jumps to specific positions in the first half. The second "The" attends to " cat" (the token after the first "The"). This head implements the second step: querying "who has predecessor equal to my current token?" and copying that position's token to the output.These attention patterns are from actual GPT-2 Small runs in TransformerLens, not idealized illustrations. Real attention patterns are messier than textbook diagrams -- notice that the previous token head has some diffuse attention beyond the strict diagonal, and the induction head has background attention to various positions. The diagnostic patterns are strong enough to identify the head types, but interpreting attention requires looking at the dominant structure, not expecting perfect textbook examples.
These visualizations let us see the two-step mechanism we studied theoretically. But attention patterns reveal only where a head looks, not what it does with the information. The attention pattern comes from the QK circuit. What information gets moved comes from the OV circuit. Two heads with identical attention patterns can have completely different effects on the output.
What Attention Patterns Can and Cannot Tell Us
Attention patterns show where heads look. They reveal structural patterns like diagonal (previous token) and off-diagonal (induction) that provide clues about head function. But they do not tell us what information the head moves or whether the attended information matters downstream.
A head attends to the previous token, but does that attention matter for the output? The attention pattern establishes a correlation: the head looks at certain positions. To establish causation, we need intervention experiments like activation patching where we change the model's internals and observe changes in behavior.
Observation reveals where attention flows. Only intervention reveals what matters.