The Other Half of the Transformer
Every transformer layer has two components. Attention moves information between positions, letting tokens communicate across the sequence. But after attention has routed information, a second component processes it: the MLP (multi-layer perceptron), also called the feed-forward network. Unlike attention, the MLP operates independently on each position. It does no cross-token communication. Instead, it transforms the information that attention has gathered, applying nonlinear computations within each position.
MLPs hold roughly two-thirds of a transformer's parameters, yet for years their function remained opaque. While attention heads have interpretable structure (queries match keys, values get copied), the MLP is just a matrix multiply, a nonlinearity, and another matrix multiply. What could it possibly be doing with all those parameters?
A series of results from 2020 to 2023 changed this. We now have a coherent mechanistic picture of what MLPs do, built from three increasingly detailed levels of analysis.
The MLP Equation
The architecture article introduced the MLP as a local computation step. Here is the full equation:
where projects the -dimensional residual stream to a hidden layer of dimension (typically ), is a nonlinear activation (GELU in GPT-2), and projects back down. This is the standard two-layer feed-forward network.
The up-projection to a wider hidden layer followed by a down-projection creates an expansion-compression bottleneck. The model has "slots" in the hidden layer, each of which can activate (or not) on a given input. The nonlinearity acts as a gate, determining which slots fire. The output is a weighted combination of contributions from the active slots.
The residual stream is updated additively:
where is the residual stream after attention in layer . Like attention, the MLP reads from and writes to the residual stream. Its contribution can be isolated and measured independently.
MLPs as Key-Value Memories
The first insight came from examining the structure of the MLP computation more carefully [1]Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., Levy, O.
EMNLP, 2021. Consider what happens when we expand the matrix multiplication:
where is the -th row of (the "key" for neuron ) and is the -th column of (the "value" for neuron ). We have dropped the biases for clarity.With the bias terms included, the activation becomes , which shifts the threshold at which neuron activates. The value vector is still , and the output still sums over active neurons. The key-value interpretation holds with or without biases.
Key-Value Memory (MLP): Each of the neurons in an MLP layer acts as a key-value pair. The key (a row of ) computes a match score with the input via a dot product. If the match passes the nonlinearity, the value (a column of ) is added to the output, scaled by the activation strength. The MLP output is a weighted sum of value vectors from all active neurons.
This is not a metaphor. The computation is structurally identical to a soft key-value lookup: the input is matched against a bank of keys, and the corresponding values are retrieved and combined. The nonlinearity acts as a soft gate, determining which key-value pairs are active for a given input.
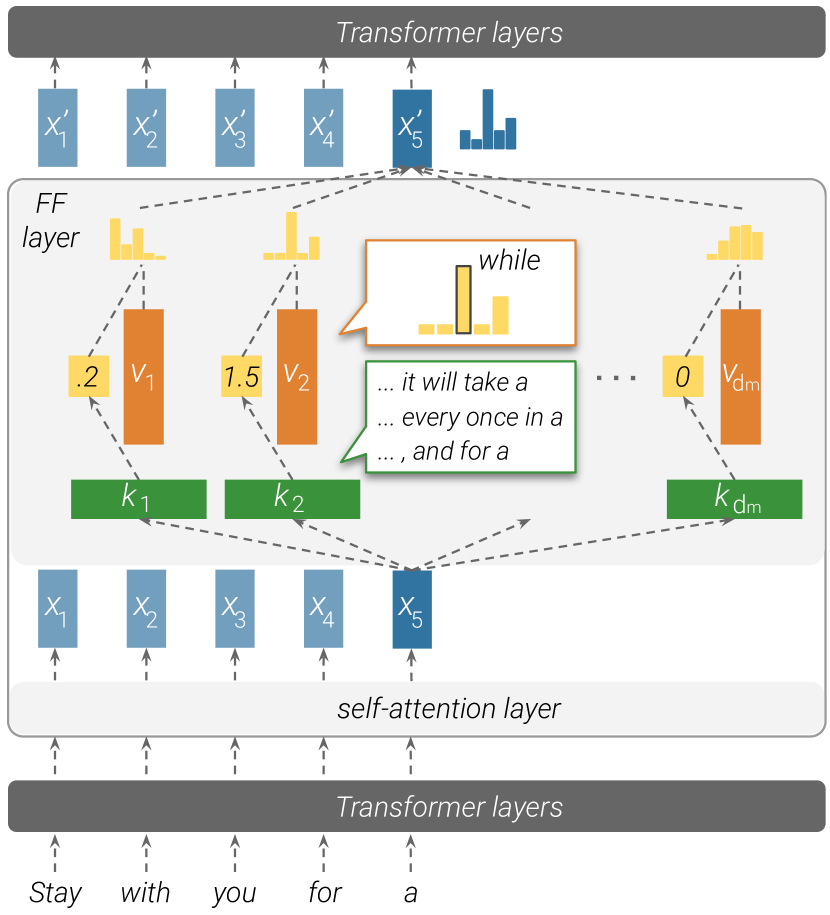
Geva, M., Schuster, R., Berant, J., Levy, O.
EMNLP, 2021
Geva et al. studied a 16-layer transformer and examined what the keys and values actually encode [3]Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., Levy, O.
EMNLP, 2021. By collecting the inputs that maximally activate each neuron (the inputs that best match each key), they found interpretable patterns:
- Lower layers (1-9): Keys predominantly match shallow textual patterns. Neuron in layer 3 might activate on inputs containing specific n-grams, punctuation patterns, or syntactic constructions.
- Upper layers (10-16): Keys match semantic patterns. Neuron in layer 14 might activate on inputs about European geography, regardless of the specific wording.
This stratification mirrors what we see with attention heads (earlier layers handle syntax, later layers handle semantics), but here it arises in a different component and through a different mechanism. Attention heads learn where to look. MLP neurons learn what patterns to recognize and what information to retrieve in response.
Sparse Activation
Not every neuron fires on every input. Geva et al. found that only about 10-50% of the neurons in a given layer activate for any particular input [4]Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., Levy, O.
EMNLP, 2021. This means the MLP output is dominated by a relatively small subset of value vectors on each forward pass.
This sparsity is not just an empirical curiosity. Zhang et al. showed that MLP neurons naturally cluster into functional groups, and that routing each input to only the relevant 10-30% of neurons preserves over 95% of model performance [5]MoEfication: Transformer Feed-forward Layers Are Mixtures of Experts
Zhang, Z., Lin, Y., Liu, Z., et al.
ACL Findings, 2022. In effect, the dense MLP already behaves like a sparse mixture of experts, even though it was not designed or trained to be one.This observation connects to a broader finding about activation sparsity in transformers. As models scale, activation sparsity tends to increase: larger models use a smaller fraction of their MLP neurons for any given input. This is part of why sparse autoencoders work well on MLP activations, and why transcoders can replace MLPs with wider but sparser alternatives.
The practical implication is that the MLP at each layer applies a different subset of its key-value memory to each input. When the model processes "The Eiffel Tower is in ___", the active neurons at layer 10 might be those whose keys match geographic entities and European landmarks, while the neurons matching, say, programming syntax remain inactive.
Pause and think: Keys and values
Consider the MLP equation decomposed as a sum over neurons: . If you had access to the weight matrices of a trained model, how would you investigate what a specific neuron "knows"? What would you look at to understand key , and what would you look at to understand value ?
For the key: you could collect many inputs and find which ones produce the highest dot product (i.e., which inputs maximally activate the neuron). The common patterns among these inputs tell you what the neuron detects. For the value: you need to know what the value vector does when added to the residual stream. The next section shows how.
Values Promote Concepts in Vocabulary Space
Knowing that neurons match patterns (keys) and retrieve information (values) is a start, but what kind of information do the values encode? Geva et al. answered this by projecting value vectors through the unembedding matrix [6]Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Geva, M., Caciularu, A., Wang, K., Goldberg, Y.
EMNLP, 2022.
Recall that the model's output is computed by multiplying the final residual stream by the unembedding matrix to get logits over the vocabulary. Because the MLP output is added to the residual stream, and is a linear map, each value vector has a direct effect on the output logits:
This projection gives us a distribution over the vocabulary for each neuron. We can read off which tokens neuron promotes (positive logit contribution) and which it suppresses (negative contribution).
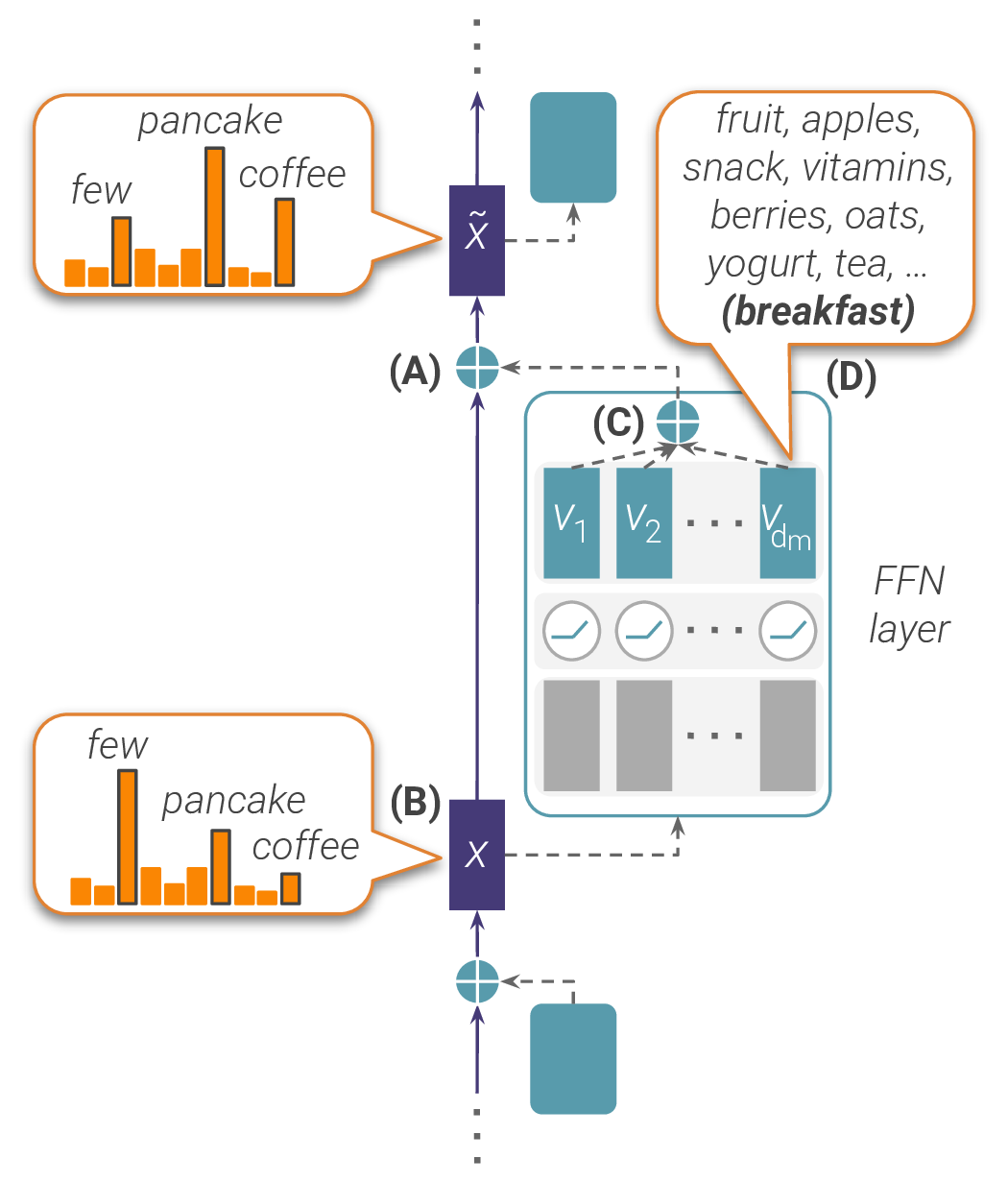
Geva, M., Caciularu, A., Wang, K., Goldberg, Y.
EMNLP, 2022
When Geva et al. examined these projections across a model's neurons, the results were strikingly interpretable [8]Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Geva, M., Caciularu, A., Wang, K., Goldberg, Y.
EMNLP, 2022. Individual value vectors promote coherent concepts, not random tokens. A value vector might promote the cluster {Paris, France, French, European, Seine}, or the cluster {multiply, divide, arithmetic, calculate}. The promoted tokens share a semantic theme that corresponds to the pattern matched by the key.
This gives us a complete picture of what individual MLP neurons do: the key detects a pattern in the input, and the value promotes a related concept in vocabulary space. The MLP output is a sum of concept-promoting sub-updates:
where is the activation coefficient for neuron . Each active neuron nudges the residual stream in a direction that promotes its associated concept. The combined effect builds up a prediction through the superposition of many concept-promoting contributions.This additive structure is why direct logit attribution works: because each MLP layer's contribution to the logits decomposes as a sum of per-neuron terms, we can attribute the output to individual neurons. The value-vector projection is simply DLA applied at the sub-MLP-layer granularity.
Roughly 68% of MLP outputs represent compositional predictions: the resulting top tokens differ from what any single neuron would promote on its own [9]Transformer Feed-Forward Layers Are Key-Value Memories
Geva, M., Schuster, R., Berant, J., Levy, O.
EMNLP, 2021. The neurons collaborate. No single neuron encodes "predict Paris." Instead, several neurons promote overlapping aspects (European places, capital cities, French things), and their combined signal converges on "Paris."
Knowledge Neurons
If individual MLP neurons promote specific concepts, can we find the neurons responsible for specific facts? Dai et al. investigated this using integrated gradients on BERT's fill-in-the-blank task [10]Knowledge Neurons in Pretrained Transformers
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., Wei, F.
ACL, 2022.
Knowledge Neuron: A knowledge neuron is an MLP neuron whose activation is causally linked to a specific factual association. Suppressing it degrades the model's ability to express the fact; amplifying it strengthens the expression.
The results were sharp. Suppressing the top knowledge neurons for a given fact reduced the model's probability of producing the correct answer by 29% on average, while suppressing a random set of neurons of the same size had only a 1.5% effect. Amplifying knowledge neurons boosted the correct probability by 31% [11]Knowledge Neurons in Pretrained Transformers
Dai, D., Dong, L., Hao, Y., Sui, Z., Chang, B., Wei, F.
ACL, 2022.The knowledge neurons work studied BERT, an encoder-only model, using its fill-in-the-blank (masked language modeling) task. The findings about specific neurons controlling specific facts have been broadly validated in autoregressive models as well, though the details of which layers and neurons matter differ between architectures.
This provides causal evidence that MLP neurons are not just correlated with factual knowledge but are directly involved in producing it. The key-value memory view is not just a useful analogy; specific key-value pairs in the MLP are causally necessary for recalling specific facts.
The Factual Recall Pipeline
The studies above explain what individual MLP neurons do, but factual recall in a full transformer is not a single-step lookup. When the model processes "The Eiffel Tower is located in ___" and predicts "Paris," information must flow from the subject tokens ("Eiffel Tower") through the network to the prediction position. How is this orchestrated?
Geva et al. traced this pipeline end-to-end and identified three stages [12]Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Geva, M., Bastings, J., Filippova, K., Globerson, A.
EMNLP, 2023:
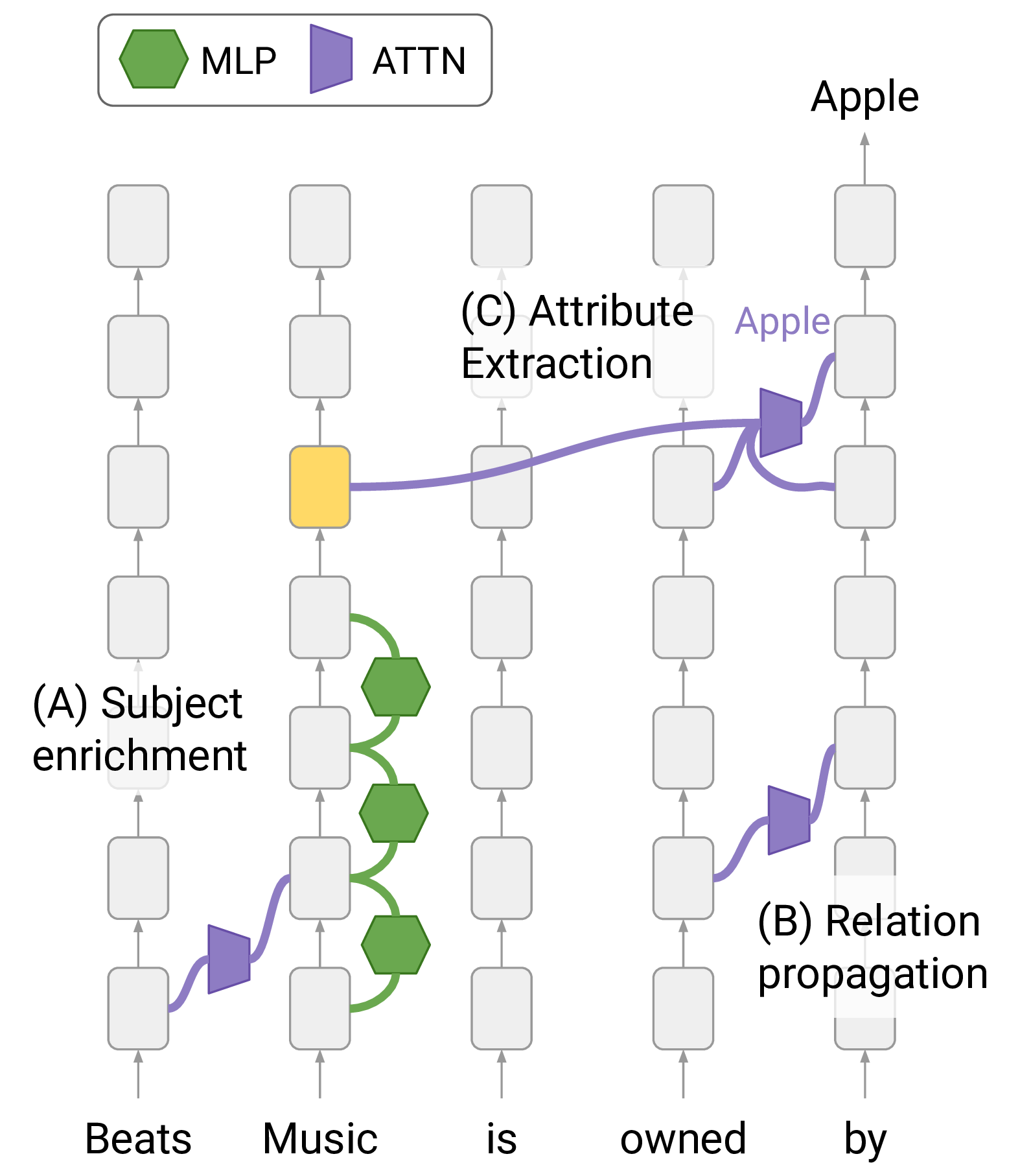
Geva, M., Bastings, J., Filippova, K., Globerson, A.
EMNLP, 2023
Stage 1: Subject enrichment (early MLP layers). At the position of the subject tokens ("Eiffel Tower"), early MLP layers enrich the representation with multiple attributes associated with the subject. After these layers, the residual stream at the subject position encodes not just the identity of the entity but a bundle of associated properties: location (Paris, France), type (landmark, tower), material (iron), and more. The MLP neurons doing this work are exactly the key-value memories described above: their keys match the subject pattern, and their values inject associated attributes.
Stage 2: Relation propagation (attention in middle layers). The relation tokens ("is located in") signal what kind of attribute is being queried. Attention heads in the middle layers propagate this relational signal to the final prediction position, setting up the query that will extract the answer. After this stage, the residual stream at the prediction position contains information about both the subject and the relation.
Stage 3: Attribute extraction (late attention heads). Attention heads at the prediction position attend back to the enriched subject representation and extract the specific attribute that matches the relation. These late attention heads effectively look up "the location attribute of the entity at the subject position" and write the answer ("Paris") to the prediction position, where it boosts the correct token's logit.The three-stage pipeline is a useful simplification. In practice, the boundaries between stages are not sharp, and some information flows through parallel pathways. But the core insight holds: early MLPs enrich subjects with attributes, and later attention heads extract the relevant attribute based on the relation.
Pause and think: Why ROME targets mid-layer MLPs
ROME edits factual associations by performing a rank-one update to a specific MLP layer's weight matrix. The technique targets mid-layer MLPs, not early layers, not late layers, and not attention heads. Given the three-stage factual recall pipeline, why would mid-layer MLPs be the right target?
Mid-layer MLPs sit at the boundary between subject enrichment and relation propagation. They are the last point where the model writes subject-associated attributes before attention heads begin extracting them. Editing the MLP at this stage modifies what attributes are available for extraction. Editing earlier layers would affect the raw subject representation (potentially disrupting many facts), and editing later layers would miss the window before extraction begins. This is the mechanistic justification for causal tracing's finding that mid-layer MLP restorations most strongly recover factual predictions.
Connections Across the Course
The MLP-as-knowledge-storage view connects to several techniques covered elsewhere in the curriculum:
Logit lens. The logit lens projects intermediate residual streams into vocabulary space, revealing how predictions evolve layer by layer. The gradual refinement it reveals (e.g., "France" at layer 4 transitioning to "Paris" at layer 6) is a direct consequence of successive MLP layers promoting increasingly specific concepts. Each MLP layer adds its value-vector contributions, and the vocabulary-space projection shows the cumulative effect.
Direct logit attribution. DLA decomposes the output into per-component contributions. The MLP terms in that decomposition () are exactly the summed value-vector contributions from layer . Understanding that MLPs promote concepts explains why individual MLP layers often have strong, interpretable DLA signatures.
Transcoders. Transcoders replace opaque MLP layers with sparse, interpretable alternatives. The motivation for transcoders becomes clearer with the key-value memory picture: if we already know that MLP neurons detect patterns and promote concepts, a transcoder makes these patterns and concepts explicit and traceable through the circuit. Transcoders decompose the same computation that the key-value view describes, but in a form that supports circuit analysis.
Model editing. ROME treats the MLP as a key-value memory and edits facts by modifying the value associated with a subject's key. The three-stage pipeline explains why this targets specific layers and why the editing has limitations: editing one MLP layer changes the attributes available at that layer, but earlier and later layers may still encode the original fact through redundant pathways.
Limitations
The key-value memory view, while productive, has important caveats.
Individual neurons are not the whole story. The clean "one neuron, one concept" picture holds for some neurons but not all. Many neurons are polysemantic, responding to multiple unrelated patterns. The key-value memory interpretation works best for neurons with clear, monosemantic keys. Superposition means that the true units of analysis may be directions in activation space, not individual neurons, which is part of why sparse autoencoders exist.
The three-stage pipeline is a simplification. Factual recall involves parallel pathways, redundant encoding, and interactions between attention and MLPs that the clean three-stage story glosses over. Different facts may follow different retrieval pathways, and the boundaries between stages are not sharp.
Causation is hard to establish. Observing that a value vector promotes "Paris" in vocabulary space does not prove that the neuron is causally responsible for the model predicting "Paris" on a given input. Many neurons promote overlapping concepts, and the prediction emerges from their combination. Causal methods like activation patching remain necessary to confirm which neurons actually matter for specific predictions.
Looking Ahead
We now have a mechanistic picture of both components in a transformer layer. Attention moves information between positions. MLPs process that information at each position through key-value memories that promote concepts in vocabulary space. Together, they implement a staged pipeline for tasks like factual recall: MLPs enrich representations with associated attributes, and attention heads route and extract the relevant information.
The next article, Layer Normalization, covers the normalization step that appears before each sublayer and why it introduces a nonlinearity that complicates the clean additive decomposition we rely on for mechanistic analysis.