Beyond Single-Layer SAEs
Standard sparse autoencoders operate on a single activation vector from one layer of one model. This is a powerful tool for decomposing individual layers, but it misses two things: features that persist across layers, and features that differ across models.
Consider a feature like "this token is a proper noun." With per-layer SAEs, this feature might be rediscovered independently at layers 3, 5, 8, and 12. Each SAE finds it anew, creating redundant representations and obscuring the fact that it is a single persistent feature. Cross-layer superposition (the same concept spread across layers) is invisible to per-layer decomposition.The refusal direction finding hints at this problem from a different angle. A single direction mediates refusal across layers. Per-layer SAEs might capture this direction at each layer but would not naturally connect those per-layer representations into a unified picture.
Similarly, when comparing a base model and its fine-tuned variant, separate SAEs trained on each model produce incompatible dictionaries. We cannot directly ask "which features are shared?" because the two SAEs learned different decompositions.
Crosscoders solve both problems by training a single dictionary across multiple sources simultaneously.
From SAEs to Crosscoders
In sparse autoencoders, the encoder reads from a single activation vector at one layer of one model, and the decoder reconstructs that same vector through a sparse bottleneck.
Crosscoder: A crosscoder is a sparse autoencoder variant that reads from (and writes to) concatenated activations from multiple layers or multiple models. It learns a shared dictionary of features across all sources simultaneously. Where a standard SAE operates on a single activation vector , a crosscoder operates on the concatenation of activations from multiple sources:
The crosscoder learns a single dictionary. For each dictionary element, it learns a pair of latent directions -- one per model (or one per layer, in the cross-layer case). This forces the crosscoder to find common structure across sources while also representing source-specific features.
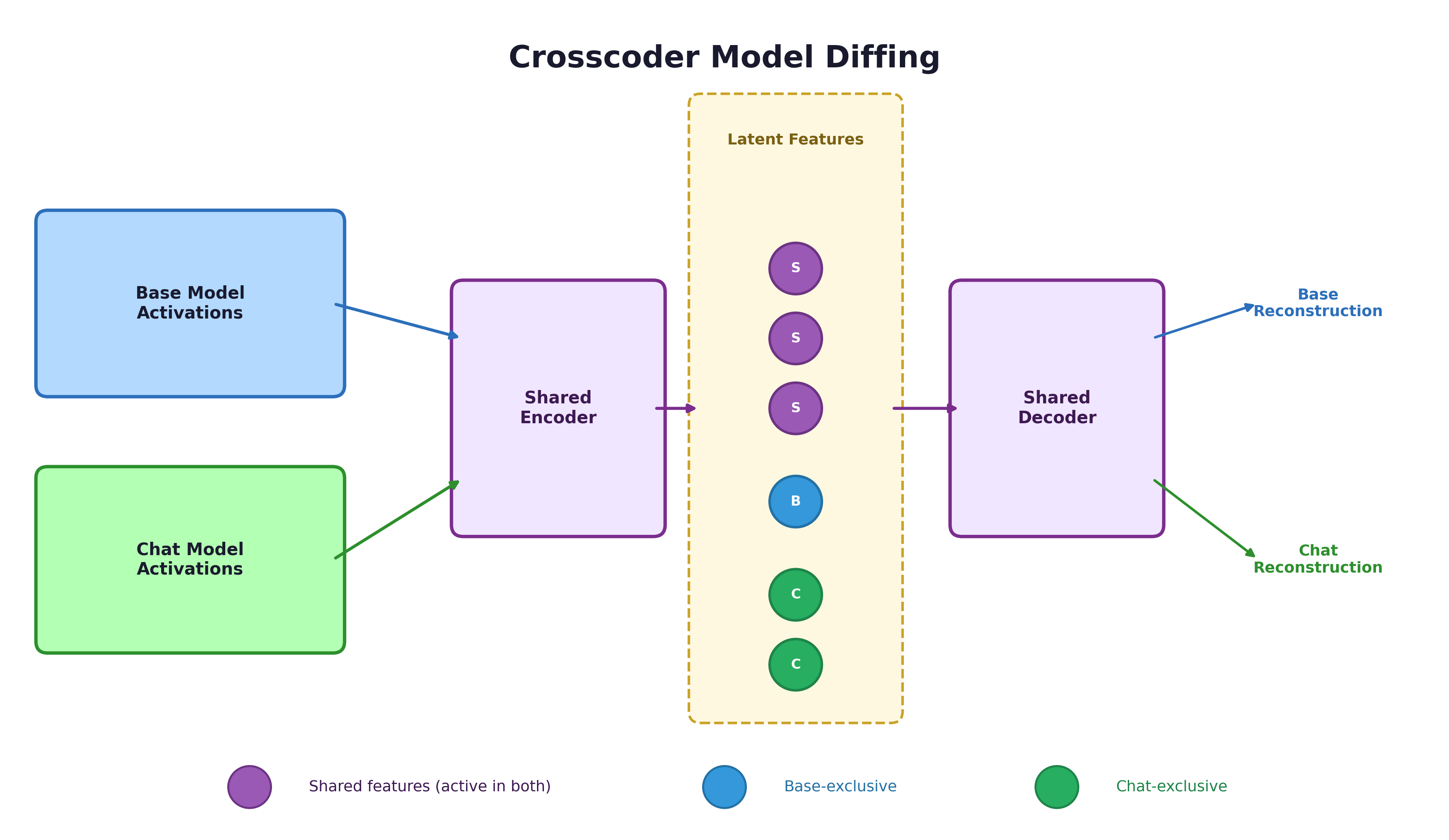
Three Applications
Crosscoders have three main uses:
-
Cross-layer features: Track features that persist across layers in the residual stream, resolving cross-layer superposition. A feature like "this token is a proper noun" might be active from layer 3 through layer 15; a crosscoder represents it once rather than rediscovering it at each layer.
-
Circuit simplification: By identifying persistent features, crosscoders remove redundant "identity" connections from circuit analysis. If a feature simply passes through several layers unchanged, the crosscoder collapses those connections into a single node.
-
Model diffing: Train a crosscoder on activations from two models to discover what they share and where they differ. This is the most safety-relevant application.
The Training Objective
The crosscoder training objective mirrors standard SAEs, applied to the concatenated input:
The reconstruction term ensures all sources are faithfully represented. The sparsity term encourages each feature to be active in only a few inputs. The shared dictionary forces the crosscoder to find common structure across sources.The loss function treats all sources equally. In principle, you could weight one source more heavily to prioritize faithful reconstruction of that source. In practice, equal weighting works well because the shared features dominate and the equal treatment prevents the crosscoder from ignoring the source with fewer unique features.
Pause and think: Why concatenation?
Why does the crosscoder concatenate activations from multiple sources rather than, say, training separate encoders with a shared bottleneck? What property of the concatenation approach forces the crosscoder to find shared structure?
The concatenation means a single encoder must find features that explain variation across all sources simultaneously. If a concept exists in both the base and chat model, the most efficient representation is a single shared feature. Separate encoders could find independent features for each source, even for shared concepts, which would defeat the purpose. The shared encoder under concatenation is what creates the pressure to discover genuinely shared vs. source-specific features.
Crosscoders in the SAE Family
Crosscoders fit naturally into the progression of SAE architectures:
- Standard SAEs decompose a single layer's activations into sparse features.
- Transcoders decompose MLP computations (input → output) rather than representations, enabling circuit tracing through MLPs.
- Crosscoders decompose joint activations from multiple sources, enabling cross-source comparison.
Each variant extends the core idea of sparse dictionary learning to answer a different question. SAEs ask "what features are present here?" Transcoders ask "what function is computed here?" Crosscoders ask "what is shared and what differs across these sources?"
The model diffing application of crosscoders -- comparing base and fine-tuned models to understand what safety training changes -- is covered in detail in Feature-Level Model Diffing.
Key Takeaways
- Crosscoders extend SAEs to operate across multiple layers or models, learning a shared dictionary from concatenated activations.
- Three applications: resolving cross-layer superposition, simplifying circuits by collapsing persistent features, and comparing models via shared dictionaries.
- Crosscoders complement CKA and SVCCA, which measure representation similarity holistically. CKA tells you whether models are similar; crosscoders tell you how they differ.
- The model diffing application is particularly safety-relevant. For a deep dive into applying crosscoders to understand fine-tuning, see Feature-Level Model Diffing.