From Head-Level to Feature-Level Circuits
In the IOI circuit analysis, we traced the mechanism by which GPT-2 Small identifies indirect objects. The circuit had 26 attention heads organized into 7 functional classes. This was a landmark result, but the nodes in that circuit -- attention heads -- are polysemantic components that participate in many unrelated behaviors. The IOI circuit told us which heads matter, but each head was doing many things beyond the IOI task.
Sparse autoencoders changed the picture by providing monosemantic features -- individual directions in activation space that correspond to single, interpretable concepts. The natural next step: use SAE features as the nodes in circuit graphs, replacing polysemantic heads with monosemantic features. This gives us higher resolution and more interpretable circuits.
Two lines of work made this possible. First, sparse feature circuits [1]Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, S., Rager, C., Michaud, E. J., et al.
ICLR 2025, 2024 demonstrated that SAE features can serve as causally implicated circuit nodes. Second, attribution graphs [2]Circuit Tracing: Revealing Computational Graphs in Language Models
Lindsey, J., Batson, J., Denison, C., et al.
Anthropic, 2025 combined cross-layer transcoders with backward Jacobian tracing to build complete feature-level circuit maps. Together, they represent the current frontier of circuit analysis.
Sparse Feature Circuits
Marks et al. (2024) asked a simple question: can SAE features serve as the nodes in causal circuit graphs? The answer is yes, and the resulting sparse feature circuits bridge SAE feature discovery with causal circuit analysis.The term 'sparse feature circuits' emphasizes both properties: the features are sparse (from SAEs) and they form circuits (causal graphs). This distinguishes them from earlier head-level circuits where nodes are dense, polysemantic attention heads.
The pipeline works in four steps:
- Train SAEs on model activations at each layer, producing interpretable features
- Identify causally responsible features using activation patching -- for a given behavior, which features matter?
- Build a graph where nodes are SAE features and edges represent causal effects between features across layers
- Prune the graph to retain only edges with significant causal effect
SHIFT: Human-Editable Circuits
An important contribution of Marks et al. is SHIFT (Spurious Human-interpretable Feature Trimming). After discovering a feature circuit, a human inspects the features and identifies those that seem task-irrelevant. Ablating these "spurious" features changes the model's generalization behavior -- demonstrating that feature circuits are not just descriptive but editable.
SHIFT bridges the gap between "we found the circuit" and "we can change what the circuit does." This is a concrete step toward using MI for model control, not just model understanding.
Scalable Unsupervised Discovery
Beyond individual circuits, Marks et al. built a scalable unsupervised pipeline that automatically discovers thousands of feature circuits for model behaviors found via SAE feature clustering. No human supervision is needed for the initial discovery phase -- human inspection is reserved for validation and editing. This moves circuit discovery from a labor-intensive per-task endeavor toward an automated process.
Limitations of Sparse Feature Circuits
Sparse feature circuits demonstrated the concept, but the approach has important limitations:
- It relies on per-layer SAEs. Features do not naturally cross MLP boundaries, so the circuits cannot trace information through MLP computations.
- Patching is computationally expensive at scale. Each feature must be individually patched, and large models have millions of features.
- Each circuit is task-specific -- discovering a new circuit for a new behavior requires running the full pipeline again.
Attribution graphs address these limitations by replacing MLPs entirely with cross-layer transcoders and using efficient Jacobian tracing instead of brute-force patching.
Attribution Graphs
Lindsey et al. (2025) proposed attribution graphs: a method for tracing circuits through language models at the level of individual features [3]Circuit Tracing: Revealing Computational Graphs in Language Models
Lindsey, J., Batson, J., Denison, C., et al.
Anthropic, 2025. The approach has two parts: build a replacement model where MLPs are replaced by cross-layer transcoders, then trace backward from the output through the feature network.
Cross-Layer Transcoders
A regular transcoder reads from one layer's MLP input and writes to that layer's MLP output. A cross-layer transcoder (CLT) extends this idea: it reads from the residual stream at one layer and contributes to all subsequent MLP layers. Features in a CLT can bridge across multiple layers, making cross-layer interactions explicit.Why does bridging matter? Many features persist across layers -- for example, 'this token is a proper noun' might be relevant from layer 3 through layer 15. With per-layer SAEs, this feature is rediscovered independently at each layer. With CLTs, it is represented once, and its influence on all downstream layers is captured in a single set of decoder weights.
Cross-Layer Transcoder (CLT): A CLT extends the transcoder concept by reading from the residual stream at one layer and writing to multiple subsequent layers. Features in a CLT can bridge across multiple MLP layers, making cross-layer interactions explicit. When all MLPs in a model are replaced by CLTs, the resulting replacement model has an interpretable sparse structure where feature-to-feature interactions are linear for any given input.
The Replacement Model
The attribution graph method works on a replacement model, not the original:
- Train CLTs to approximate the behavior of all MLP layers simultaneously
- Replace the MLPs with the trained CLTs
- The replacement model behaves similarly to the original but has an interpretable sparse structure
A key property of the replacement model: for a specific input, the feature-to-feature interactions are linear. This is because attention patterns are fixed once computed for a given input, layer normalization denominators are fixed, and feature activations are sparse and known. The direct effect of one feature on another is a linear function of that feature's activation, computable exactly via the backward Jacobian.
How Graphs Are Constructed
For a specific input:
- Run the replacement model and record all active features, their activations, and the output logits
- Choose a target output -- for example, the logit for a specific predicted token. This becomes the root of the graph.
- Trace backward via the Jacobian. For each active feature, compute its linear effect on the target output. Keep features whose effect exceeds a threshold.
- Recurse. For each retained feature, trace backward to find which earlier features (or input embeddings) contributed to its activation. Continue until reaching the input.
The resulting graph has nodes (CLT features, token embeddings, reconstruction errors, and output logits), edges (linear effects between nodes, weighted by magnitude), and a clear direction from input embeddings through features to output logits.
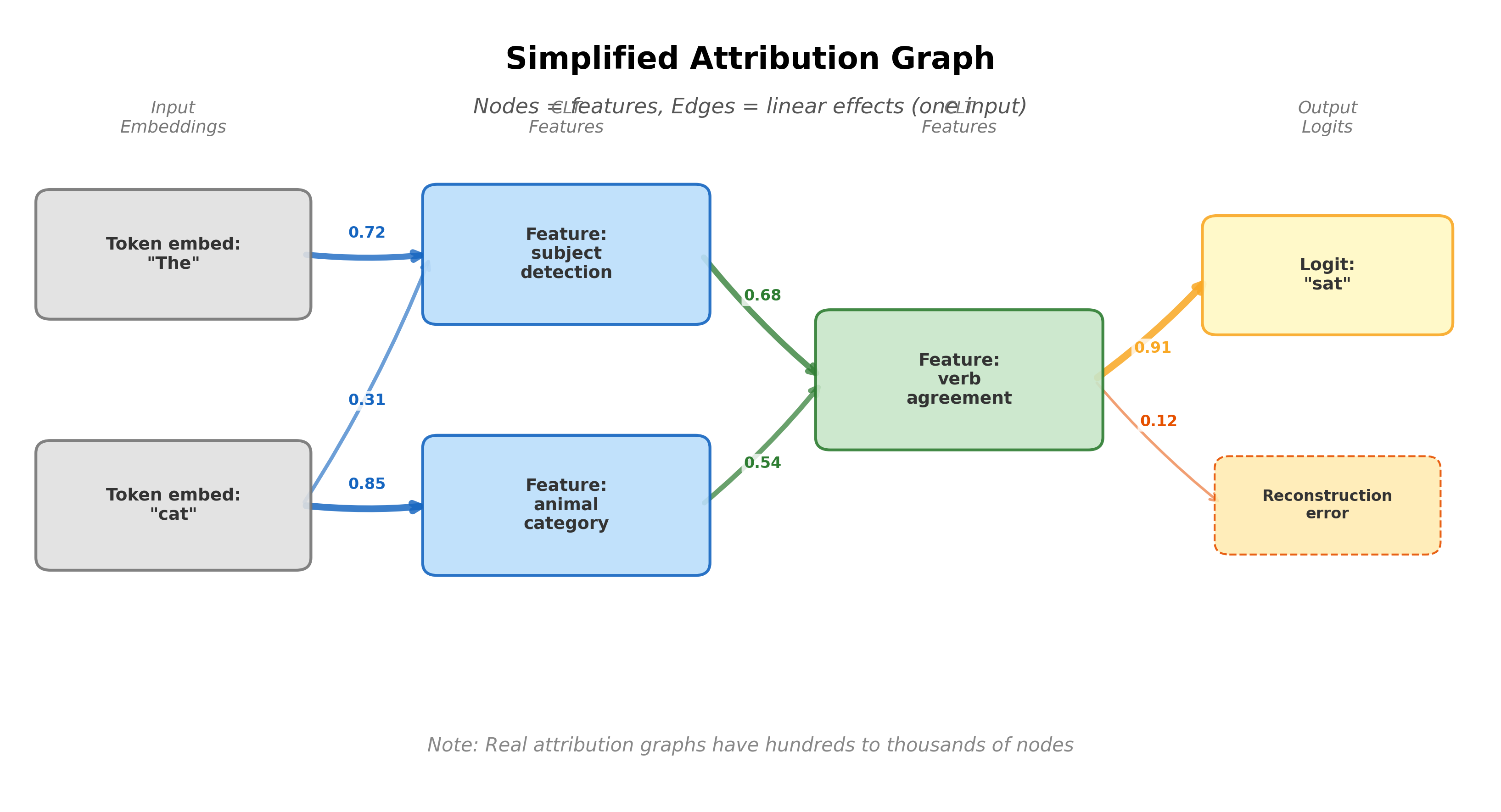
Case Studies from the Biology Paper
Anthropic (2025) applied attribution graphs to Claude 3.5 Haiku, producing a companion paper titled "On the Biology of a Large Language Model" [4]On the Biology of a Large Language Model
Anthropic
Anthropic, 2025. The paper presents detailed case studies of what attribution graphs reveal about the model's internal processing.
Multi-Step Reasoning
When asked "What is the capital of the country containing the city of Dallas?", the attribution graph reveals a chain of features:
- A "Dallas" feature activates, recognizing the city
- This activates a "Texas" feature -- a geographic association
- The "Texas" feature activates a "United States" feature -- state-to-country mapping
- The "United States" feature activates a "Washington D.C." feature -- capital knowledge
Each step is a distinct feature-to-feature connection visible in the graph. The model does not jump from "Dallas" to "Washington D.C." in one step; it follows a multi-step path through intermediate geographic representations. This is consistent with the hypothesis that transformers implement multi-step algorithms through sequential feature activation across layers.
Multilingual Processing
When processing text in a non-English language, the attribution graph reveals a three-phase pattern. Early features encode language-specific tokens (French words, grammar patterns). Intermediate features are language-agnostic -- they encode meaning rather than surface form. Late features translate from the shared meaning representation back to the target language. The model appears to use a shared conceptual space across languages, with language-specific features at the input and output boundaries.
Poetry and Rhyme
When completing a poem where the next word must rhyme, the attribution graph reveals two parallel pathways: a semantic pathway encoding the meaning and theme of the poem, and a phonetic pathway encoding the sound pattern and rhyme constraint. These pathways converge at the output, producing a word that satisfies both meaning and rhyme -- a concrete example of how multiple computational goals are solved in parallel through the feature network.
Pause and think: Per-input vs. global circuits
Attribution graphs show a chain of features for multi-step reasoning: Dallas, Texas, United States, Washington D.C. But this is the graph for one specific input. Would the model use the same chain for "What is the capital of the country containing Houston?" Would the intermediate features be identical?
What would it take to go from per-input graphs to a general understanding of how the model does geographic reasoning? You would need to run attribution graphs on many similar prompts, align the resulting graphs, and look for shared structure. This aggregation problem -- going from many individual circuit traces to a universal circuit description -- is not yet solved and remains one of the field's key open challenges.
Limitations of Current Circuit Tracing
Per-Input, Not Global
The most important limitation: attribution graphs are per-input. Each graph shows what happens on one specific prompt. Different prompts activating the same behavior can produce different graphs. There is no guarantee that the graph for "Dallas" generalizes to "Houston." Going from per-input to global circuit understanding requires aggregating many graphs -- a task that is not yet solved.This is analogous to a limitation in neuroscience. An fMRI scan shows which brain regions are active during one specific task, but inferring the general function of a brain region requires thousands of scans across many tasks and subjects. Attribution graphs are the MI equivalent of individual fMRI scans.
CLT Approximation Quality
The replacement model is an approximation. CLTs are trained to match MLP behavior, but the match is imperfect. Reconstruction error nodes in the graph capture what the CLTs miss. If the CLTs systematically fail to capture certain computations, those computations will be invisible in the graph. The quality of the attribution graph is bounded by the quality of the CLT approximation.
Active Features Only
Attribution graphs show only active features -- those that fire on the given input. Features that are inhibited (actively suppressed) may not appear. Features that would be relevant but happen to be inactive on this input are invisible. The graph shows what the model does, not what it could have done. Contrast this with the IOI analysis, where Backup Name Mover heads were discovered through ablation of the primary pathway.
Frozen Attention and Normalization
The linearity of attribution graphs depends on freezing attention patterns and layer normalization denominators. In reality, attention patterns depend on the input and change if features are modified, and layer normalization introduces nonlinear interactions. The graph shows first-order linear effects. Nonlinear interactions between features are not captured.
The Evolution of Circuit Analysis
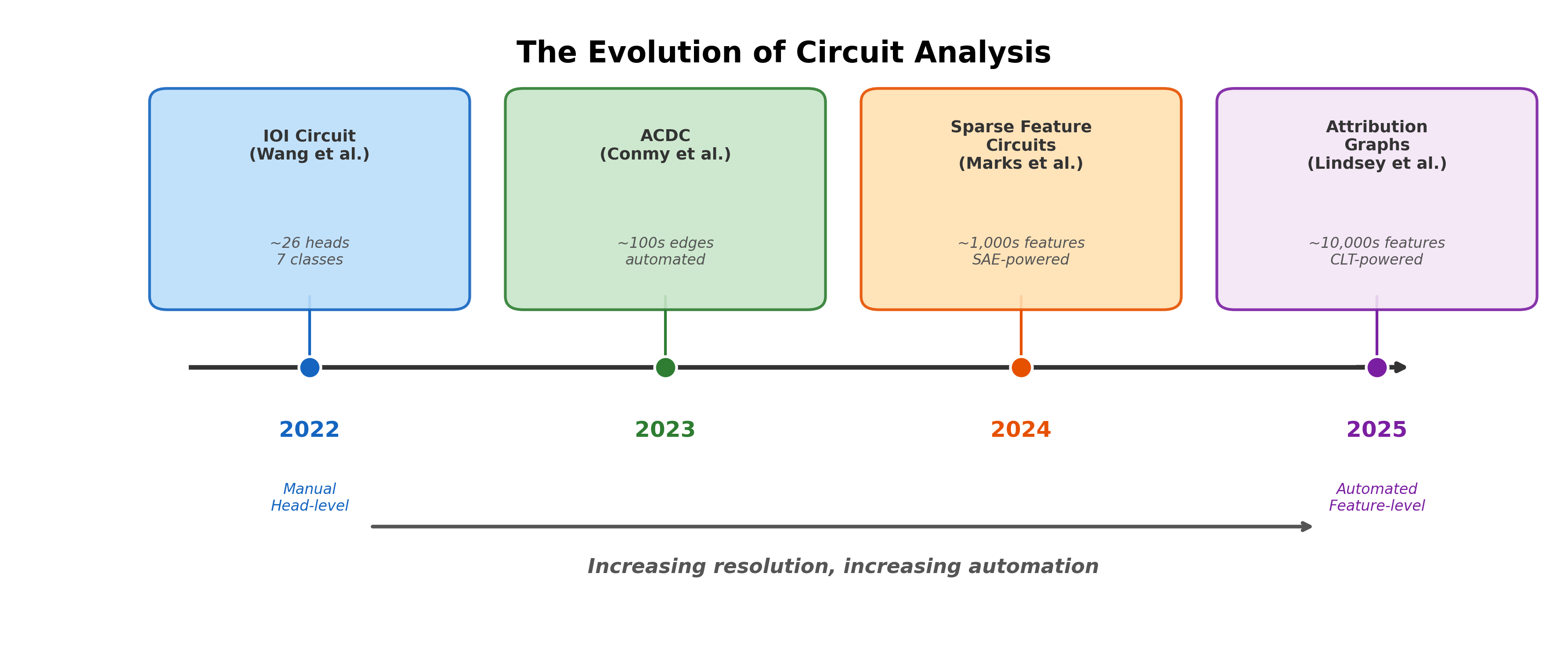
The progression tells a clear story:
- 2022: Manual head-level analysis (IOI). 26 heads, 7 classes. Months of researcher effort for one circuit in a 117M-parameter model. Nodes are polysemantic attention heads.
- 2023: Automated head-level analysis (ACDC). Conmy et al. automated path patching [5]Towards Automated Circuit Discovery for Mechanistic Interpretability
Conmy, A., Mavor-Parker, A. N., Lynch, A., et al.
NeurIPS, 2023. Still head-level granularity, but the search is algorithmic rather than manual. - 2024: Feature-level circuits (Marks et al.). SAE features as circuit nodes [6]Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Marks, S., Rager, C., Michaud, E. J., et al.
ICLR 2025, 2024. Higher resolution than heads, but still per-layer and patching-based. - 2025: Attribution graphs (Lindsey et al.). Cross-layer transcoders, Jacobian tracing, thousands of features [7]Circuit Tracing: Revealing Computational Graphs in Language Models
Lindsey, J., Batson, J., Denison, C., et al.
Anthropic, 2025. The highest resolution yet, applied to production-scale models.
Each step gained something and lost something. Higher resolution brings more detail but also more complexity. Automation brings scale but also requires more careful validation. And the fundamental challenge -- going from per-input analysis to global circuit understanding -- remains across all generations.Despite the dramatic progress, some things have not changed. Both IOI patching and attribution graphs analyze specific inputs, not general behaviors. Circuit accounts are always incomplete (87% faithfulness in IOI; reconstruction error in attribution graphs). Having a circuit diagram does not mean we fully understand the computation. Progress is real, but the hardest problems remain open.
Pause and think: What would global circuits look like?
Attribution graphs give us a per-input circuit. Imagine we could somehow aggregate thousands of attribution graphs for the same behavior into a single "global" circuit. What would that circuit look like? Would it have the same structure as individual attribution graphs, or would it be fundamentally different?
Consider that different inputs might activate different subsets of features, use different intermediate representations, or follow different computational paths to the same output. A global circuit might need to represent branching, optional paths, and input-dependent routing -- structures that are absent from individual attribution graphs. This is an open research question.
Key Takeaways
- Sparse feature circuits use SAE features as circuit nodes, bridging feature discovery with causal circuit analysis. SHIFT demonstrates that these circuits are editable, not just descriptive.
- Attribution graphs combine cross-layer transcoders with backward Jacobian tracing to produce complete feature-level circuit maps. The Biology paper shows these reveal interpretable computational chains in production models.
- Limitations are serious: per-input analysis, CLT approximation quality, active features only, and frozen attention/normalization. Attribution graphs are a tool for investigation, not a final understanding.
- The field has evolved from manual tracing of 26 attention heads (IOI, 2022) to automated tracing of thousands of features (attribution graphs, 2025). Resolution and automation have increased dramatically, but the core challenge of global circuit understanding remains.
- These tools find safety applications in detecting sleeper agents and monitoring model behavior, where feature-level circuit analysis can reveal hidden computational patterns that behavioral testing alone would miss.