Beyond Discovery
The IOI circuit tells a compelling story: 26 heads in GPT-2 Small implement a three-step algorithm for identifying indirect objects. Duplicate Token Heads detect the repeated name, S-Inhibition Heads suppress it, and Name Mover Heads output the remaining name. But finding a circuit is only half the challenge. The harder question is: how do we know this account is correct?
A circuit hypothesis can fail in subtle ways. It might miss components that matter. It might include components that do not contribute. It might reproduce the right answer for the wrong reasons. Evaluating a circuit requires criteria that distinguish genuine mechanistic explanations from plausible-sounding narratives. Wang et al. proposed three such criteria [1]Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Wang, K., Variengien, A., Conmy, A., et al.
arXiv, 2022, and the IOI circuit itself reveals why evaluation is harder than it first appears.
Negative Name Movers: Components That Work Against the Task
During direct logit attribution analysis, Wang et al. found something puzzling. Several heads in layers 10-11 have negative contributions to the logit difference. They push the model away from the correct answer (the indirect object) and toward the subject. These are the Negative Name Mover Heads, and they actively work against the circuit's task on individual examples.
Why would training produce heads that hurt performance? The leading hypothesis is loss hedging. Cross-entropy loss penalizes confident wrong predictions more harshly than uncertain correct ones. If the Name Movers sometimes make errors, Negative Name Movers reduce the confidence of those predictions, lowering the penalty.Loss hedging is a statistical optimization, not an algorithmic one. The model's training objective is average cross-entropy loss across the entire training distribution, not accuracy on individual examples. Reducing prediction confidence on examples where the model might be wrong improves the expected loss, even though it slightly hurts performance on examples where the model is right.
The practical effect: ablating a Negative Name Mover actually improves IOI performance on individual examples. The model predicts the indirect object more confidently without the hedging. But this does not mean the model is better off without it -- the hedging serves the training objective across the full distribution.
Negative Name Movers teach an important lesson: circuits can contain components that appear counterproductive when viewed in isolation. A head that hurts per-example performance may improve the model's expected loss across all training data. Naive DLA (which head helps most on this example?) can miss or misinterpret components whose function is distributional rather than per-example. Subsequent work has shown that Negative Name Movers are instances of a general copy suppression pattern: heads that attend to where a predicted token appears earlier in context and output the negative of that token's unembedding [2]Copy Suppression: Comprehensively Understanding an Attention Head
McDougall, C., Conmy, A., Rushing, C., et al.
arXiv, 2023. Copy suppression heads serve a calibration function across the full pre-training distribution, not just the IOI task.
Backup Name Movers: Built-In Redundancy
Wang et al. made another surprising discovery during ablation experiments. When primary Name Mover Heads were ablated (outputs set to zero), the model's performance did not degrade as much as expected. Something was compensating.
Closer inspection revealed: certain heads that were nearly inactive in the normal circuit activated when the primary Name Movers were removed. These are the Backup Name Mover Heads. They have the same functional profile as regular Name Movers -- they attend to name tokens, their OV circuits copy names to output logits, and they respond to S-Inhibition signals. But under normal operation, their attention weights are small and their contribution is minimal.Backup Name Movers were discovered through an iterated ablation protocol: first ablate the primary Name Movers, then run DLA on the remaining heads. Previously quiet heads suddenly show large positive contributions. This is invisible under standard patching, since the backups do not activate unless the primaries are removed.
The discovery protocol illustrates the challenge:
- Ablate the primary Name Mover Heads
- Measure the logit difference -- it drops, but not to zero
- Run DLA on the remaining heads -- previously quiet heads now show large positive contributions
- These are the Backup Name Movers
Neural network redundancy has deep implications. The circuit can tolerate partial damage and still function. But it also means that standard noising experiments underestimate the importance of primary components, because backups compensate silently. And it complicates the concept of "minimality" -- are backup components part of the circuit or not? This backup behavior is an instance of a general phenomenon called self-repair: when a model component is ablated, later components compensate through multiple mechanisms, including LayerNorm rescaling and dormant backup heads [3]The Hydra Effect: Emergent Self-repair in Language Model Computations
McGrath, T., Rahtz, M., Kramar, J., et al.
arXiv, 2023.
Pause and think: The limits of standard ablation
Backup Name Movers are invisible under normal operation and only activate when primary Name Movers are ablated. What does this imply about our ability to find all components of a circuit using standard methods?
Standard ablation tests one component at a time, holding everything else fixed. But backup mechanisms only reveal themselves when specific primary components are removed. If we have not ablated the right combination of heads, the backups remain hidden. In principle, there could be backup mechanisms for other head classes (backup S-Inhibition Heads, backup Duplicate Token Heads) that have never been discovered because the right ablation combination was never tested. The number of possible ablation combinations grows exponentially, making exhaustive search infeasible. This is a fundamental limitation of current circuit analysis methods.
The Full Circuit Diagram
With all seven head classes identified, we can now see the complete IOI circuit:
- Previous Token Heads (L0-1): shift token identity one position forward
- Duplicate Token Heads (L0-1): detect same-token matches at S2
- Induction Heads (L5-6): confirm the repeated name via K-composition
- S-Inhibition Heads (L7-8): suppress Name Mover attention to the duplicated name
- Name Mover Heads (L9-10): copy the attended name to output logits
- Negative Name Mover Heads (L10-11): reduce prediction confidence (loss hedging)
- Backup Name Mover Heads: dormant backups that activate when primary Name Movers fail
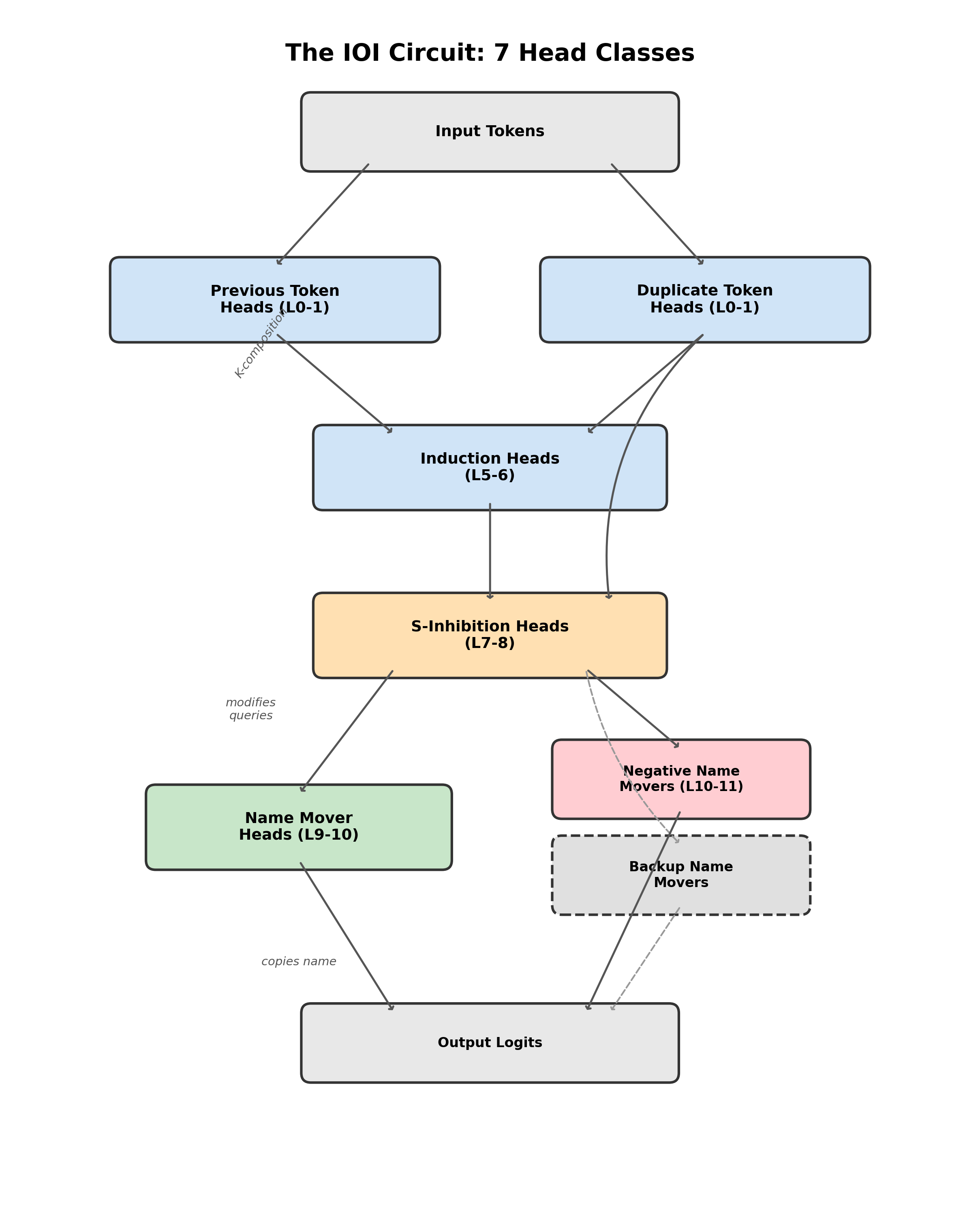
The diagram shows information flowing top to bottom through the network. The detection stage (layers 0-6) identifies which name is duplicated. The suppression stage (layers 7-8) translates detection into inhibition. The output stage (layers 9-10) copies the surviving name. Negative Name Movers and Backup Name Movers add hedging and redundancy to the primary pathway.
Evaluating Circuits: Three Criteria
Finding a circuit is a scientific claim: "these components implement this behavior." Like any scientific claim, it needs evaluation. Wang et al. proposed three criteria [4]Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Wang, K., Variengien, A., Conmy, A., et al.
arXiv, 2022:
Circuit Evaluation Criteria: A circuit for a model on task should satisfy: Faithfulness -- reproduces 's behavior on . Completeness -- includes all components that matter for . Minimality -- includes no unnecessary components.
Faithfulness asks: does the circuit reproduce the full model's behavior? The test is to run the model with only the circuit components active (ablating everything else) and compare the output to the full model. The IOI circuit recovers approximately 87% of the full model's logit difference. This is good but not perfect -- the remaining 13% comes from components outside the circuit, including MLPs and minor attention head contributions.
Completeness asks: does the circuit include everything that matters? The test is to ablate the circuit components (keeping everything else) and check if behavior collapses. Ablating the 26 IOI circuit heads reduces the logit difference dramatically, but not to zero. Some minor pathways outside the identified circuit also contribute. The circuit captures the primary mechanism but not every contributor.
Minimality asks: is every component necessary? The test is to ablate each component individually and check if behavior is unaffected. Most IOI circuit components cause performance degradation when ablated individually. But Backup Name Movers compensate for ablated primary Name Movers, and Negative Name Movers improve per-example performance when ablated. These cases show that minimality is not straightforward when circuits have redundancy and hedging.
The Tension Between Criteria
The three criteria pull in different directions. Faithfulness vs. minimality: adding more components improves faithfulness but hurts minimality. A circuit containing all 144 heads is perfectly faithful but useless as an explanation. Completeness vs. minimality: including backup mechanisms improves completeness but makes the circuit less minimal. Are backups "part of the circuit" or not?The tension between faithfulness and minimality mirrors a fundamental tradeoff in scientific explanation. A complete physical description of a system is perfectly faithful but not explanatory. A simplified model (like an ideal gas) is explanatory but not perfectly faithful. Circuit analysis faces the same tradeoff: we want explanations that are both accurate and interpretable.
There is no single right answer. The criteria form a framework for thinking about circuit quality, not a scoring rubric. The IOI circuit's evaluation -- good faithfulness (~87%), strong completeness, ambiguous minimality -- is the best evaluation in the mechanistic interpretability literature. Even so, it reveals gaps and tensions.
Causal Scrubbing
The evaluation criteria described above are intuitive but informal. Can we do better? Chan et al. at Redwood Research proposed causal scrubbing as a formal method for testing circuit hypotheses [5]Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses
Chan, L., Garriga-Alonso, A., Goldowsky-Dill, N., et al.
Redwood Research, 2022.
The core idea: an interpretability hypothesis specifies which activations should be interchangeable without affecting behavior. Causal scrubbing tests this by systematically resampling activations according to the hypothesis and checking whether behavior is preserved.
The procedure has three steps:
- Formalize the hypothesis as a computational graph where each node specifies what a component computes and which inputs matter
- Resample activations by replacing each node's activation with one sampled from a different input that matches the hypothesis about what that node computes
- Check behavior preservation -- if the model's output is preserved despite resampling, the hypothesis is consistent with the model's computation
For example, to test whether Name Mover Head 9.9 "copies whatever name it attends to, regardless of sentence structure," take two IOI sentences that differ in structure but have the same name attended by Head 9.9. Swap its activation between the sentences. If the output is preserved, the hypothesis about the head's function is consistent.
Strengths. Causal scrubbing is formal and principled, forcing hypotheses to be precise and falsifiable. It moves beyond ad-hoc evaluation (merely checking accuracy recovery) and was successfully applied to known circuits like induction heads and parenthesis matching.
Limitations. Causal scrubbing has well-documented shortcomings:
- Simultaneously too strict and too permissive. Useful but incomplete hypotheses may fail the test, while vague hypotheses can pass if they are not specific enough about what each node computes.
- Cannot distinguish extensionally equivalent hypotheses. If two different mechanistic stories produce the same input-output behavior, causal scrubbing treats them as equally valid. It tests behavior preservation, not mechanism identity.
- Distribution-dependent. Results are tied to the specific inputs used for testing. A hypothesis might pass on one prompt distribution and fail on another.
- Difficulty with redundancy. Backup mechanisms (like the IOI circuit's Backup Name Movers) break the assumption that components can be independently resampled. If component A is resampled but component B compensates, the hypothesis about A may incorrectly pass.
Perhaps the most telling limitation: Redwood Research, which developed causal scrubbing, eventually reflected that the method "was important in convincing us to stop working on [faithful explanations]." The method's own creators concluded that the bar it sets may be impractically high for current mechanistic interpretability.
Pause and think: Behavior preservation vs. mechanism identity
Causal scrubbing tests whether activations are interchangeable according to a hypothesis, but it cannot distinguish two hypotheses that make the same behavioral predictions. Is this a problem unique to causal scrubbing, or is it a fundamental limitation of any evaluation method based on behavior?
This is a fundamental limitation. Any test that only measures input-output behavior cannot distinguish mechanisms that produce identical behavior. In philosophy of science, this is called the underdetermination of theory by evidence. Two different mechanistic stories (e.g., "Head A implements token matching" vs. "Head A implements a lookup table") can produce the same activation patterns on all tested inputs. Distinguishing them would require access to a more granular level of description, or testing on inputs that would cause the two mechanisms to diverge. This is not a flaw of causal scrubbing specifically -- it is a constraint on what behavioral evaluation can achieve in principle.
Lessons from the IOI Circuit
The IOI study taught the field several principles about how transformers compute:
Compositional computation. Different layers perform different steps of an algorithm, with information flowing between them through the residual stream. The detect-suppress-output structure is a genuine multi-step algorithm, not a single-step lookup.
Functional specialization. Attention heads within a circuit have distinct, well-defined roles. Name Movers copy names. S-Inhibition Heads suppress attention. Duplicate Token Heads detect matches. Each role was verified causally, not just observed.
Emergent algorithms. The three-step algorithm was not designed by any human -- it was learned through gradient descent during training. This suggests that training discovers structured solutions to structured tasks, not arbitrary distributed representations.
Surprises. Negative Name Movers show that circuits can contain components that work against the task for statistical reasons. Backup Name Movers show that models build redundancy into their circuits. Both properties were unexpected and required specialized experiments to discover.
Limitations of Circuit Analysis
The IOI analysis is the best circuit analysis ever performed, and it still has significant limitations.
Scale. The analysis took months of researcher effort for one task in a small model (117M parameters). Manual circuit discovery does not scale to models with billions of parameters, even with semi-automated tools. ACDC (Automatic Circuit DisCovery) [6]Towards Automated Circuit Discovery for Mechanistic Interpretability
Conmy, A., Mavor-Parker, A. N., Lynch, A., et al.
NeurIPS, 2023 automates path patching by starting with a fully connected computational graph and recursively pruning edges whose activation patching effect falls below a threshold. It operates on edges (connections between components), not just nodes, producing a wiring diagram rather than a parts list. The process can be sped up significantly by using attribution patching as a fast screening step, reserving full activation patching for verification of the top candidates. Even so, ACDC requires defining a clean metric and a distribution of clean/corrupted input pairs, and the results depend on the pruning threshold.
The decomposition problem. The IOI circuit was tractable because the relevant features happened to align with individual attention heads. Each head class had a clear function. But this is not always the case. When features are distributed across many components, or when one head participates in multiple unrelated features, head-level circuit analysis breaks down.The IOI circuit uses roughly 18% of GPT-2 Small's attention heads. The other 82% participate in other circuits for other tasks. Some may participate in multiple circuits simultaneously, making it impossible to assign a single functional role to each head.
The superposition connection. The reason features do not always align with individual components has a name: superposition. Neural networks represent more features than they have dimensions by encoding features as nearly-orthogonal directions in activation space. When superposition is mild (as in IOI), each head does roughly one thing, and circuits are discoverable at the head level. When superposition is strong, features overlap, heads become polysemantic, and circuit analysis at the head level breaks down. This fundamental challenge motivates the development of sparse autoencoders and feature-level circuit tracing, which aim to decompose model internals into interpretable features before tracing circuits.
The IOI circuit remains the field's landmark case study. It demonstrated that circuit analysis is possible, that circuits implement interpretable algorithms, and that causal methods can verify circuit claims. But it also revealed the honest limitations -- incomplete faithfulness, ambiguous minimality, unscalable methodology -- that define the field's current frontier.