Why Attention?
Consider the sentence: "The cat sat on the mat because it was tired." What does "it" refer to? For a human reader the answer is obvious: "it" means the cat. But arriving at this answer requires looking back across the sentence and connecting a pronoun to the noun it references. A model that processes each token in isolation, without any ability to look at other positions, has no way to make this connection.
A simple feed-forward network applied independently at each position treats every token as if the rest of the sequence does not exist. It can transform each token's representation, but it cannot move information between positions. Pronoun resolution, subject-verb agreement, long-range dependencies: none of these are possible without some mechanism for tokens to communicate with one another.
The attention mechanism solves this problem [1]Attention Is All You Need
Vaswani, A., Shazeer, N., Parmar, N., et al.
NeurIPS, 2017. It provides a structured way for each token to look at every other token in the sequence, decide which ones are relevant, and gather information from them. Rather than processing tokens in isolation, attention lets the model build context-dependent representations where each token's output reflects the entire input it has seen so far.
Queries, Keys, and Values
Attention organizes the communication between tokens around three learned roles. Every token simultaneously plays all three:
Attention (Intuition): Each token participates in attention through three projections. The query () asks "what am I looking for?", the key () advertises "what do I contain?", and the value () provides "what information do I send if attended to?"
Each role is produced by multiplying the token's embedding by a learned weight matrix. For a token at position with embedding , the three projections are:
The projection matrices map the input down to a -dimensional query/key space, while maps to the value space. These are three different "views" of the same input, each optimized by gradient descent for a different purpose during training.
The Attention Equation
Vaswani, A., Shazeer, N., Parmar, N., et al.
NeurIPS, 2017
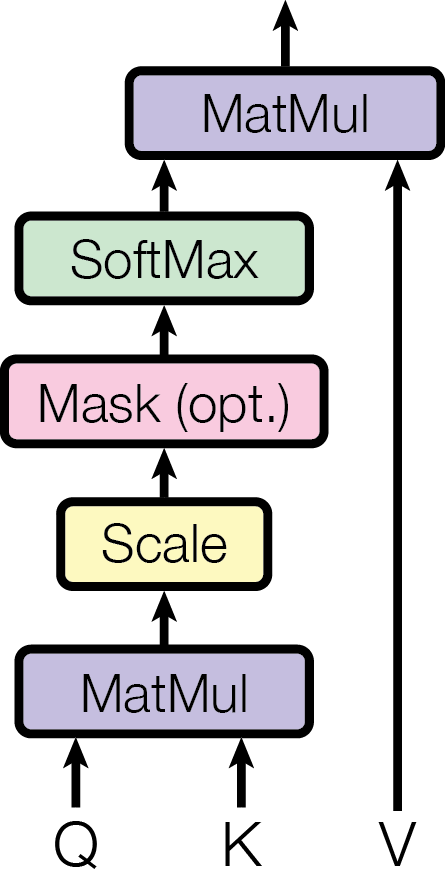
With queries, keys, and values defined, the attention mechanism proceeds in three steps: compute relevance scores, normalize them into weights, and use the weights to mix value vectors.
Step 1: Dot-product scores. How much should token attend to token ? The model measures this by computing the dot product between the query of token and the key of token :
A large dot product means the query and key point in similar directions, indicating the model has learned that these two tokens are relevant to each other.
Step 2: Scaling. The raw dot-product scores grow in magnitude with the dimension , which can push the softmax into regions with vanishingly small gradients. The fix is simple: divide by :
Step 3: Softmax normalization. The scaled scores are passed through a softmax to produce a probability distribution over positions:
Now and . Each weight tells us how much attention token pays to token .
The output. The final output for token is a weighted sum of value vectors:
In plain terms: gather information from other tokens, weighted by relevance. Tokens with high attention weight contribute more to the output; tokens with near-zero weight are effectively ignored.
Putting it all together in matrix form, where , , and stack the queries, keys, and values for all tokens:
This single equation is the core of the transformer [3]Attention Is All You Need
Vaswani, A., Shazeer, N., Parmar, N., et al.
NeurIPS, 2017. Everything else in the architecture (multi-head attention, the residual stream, MLPs) is built around it.
A Worked Example
To make the attention equation concrete, we trace a single attention head on a 3-token sequence with . The tokens are A, B, and C, and we compute the attention output for token C (the final position).
Setup. Suppose the query, key, and value vectors are:
| Token | Query | Key | Value |
|---|---|---|---|
| A | — | ||
| B | — | ||
| C |
We only need C's query (since we are computing attention from position C) and all three keys and values.
Step 1: Dot-product scores. Token C's query is compared against each key:
Step 2: Scale by . With , we divide by :
Step 3: Softmax. Converting to attention weights:
Token C attends most strongly to itself (50%), with equal attention to A and B (25% each). The self-attention is strongest because C's key aligns most with its own query (dot product of 2 vs. 1).
Step 4: Weighted sum of values. The output for token C is:
The output is dominated by C's own value vector, with smaller contributions from A and B. This is the information that this attention head writes to the residual stream at position C.
The key observation: the attention pattern (who attends to whom) is entirely determined by the dot products between queries and keys. The values are passive passengers, mixed according to whatever weights the QK interaction produces. These are two independent computations, which is the foundation of the QK/OV circuit decomposition we will develop later.
Self-Attention and Causal Masking
In self-attention, the queries, keys, and values all come from the same input sequence. Given an input matrix (one row per token), we compute , , and . The sequence attends to itself: every token can look at every other token and decide what information to gather. This is how a transformer lets all positions interact in a single step, producing context-dependent representations where each token's output reflects its relationship to the entire input.
For each token position, self-attention performs a complete information-gathering operation: it examines all other positions via the query-key match, decides how much to attend to each via softmax, collects the relevant information as a weighted sum of values, and writes the result back. Each token's output is therefore a context-dependent mixture of all tokens' value vectors.
In decoder-only transformers (such as GPT), there is an additional constraint: each token can only attend to itself and earlier tokens. This is enforced by setting for all before the softmax, which drives those attention weights to zero. This is called causal masking. The reason is simple: during autoregressive generation, future tokens do not exist yet. The model must predict the next token using only the past, so the attention mechanism must respect this constraint during both training and inference.Causal masking gives mechanistic interpretability a clean experimental setup. At each position i, we know exactly what information is available to the model: tokens 0 through i. This makes it possible to reason precisely about what the model could and could not have used to produce its output.
Multi-Head Attention
Vaswani, A., Shazeer, N., Parmar, N., et al.
NeurIPS, 2017
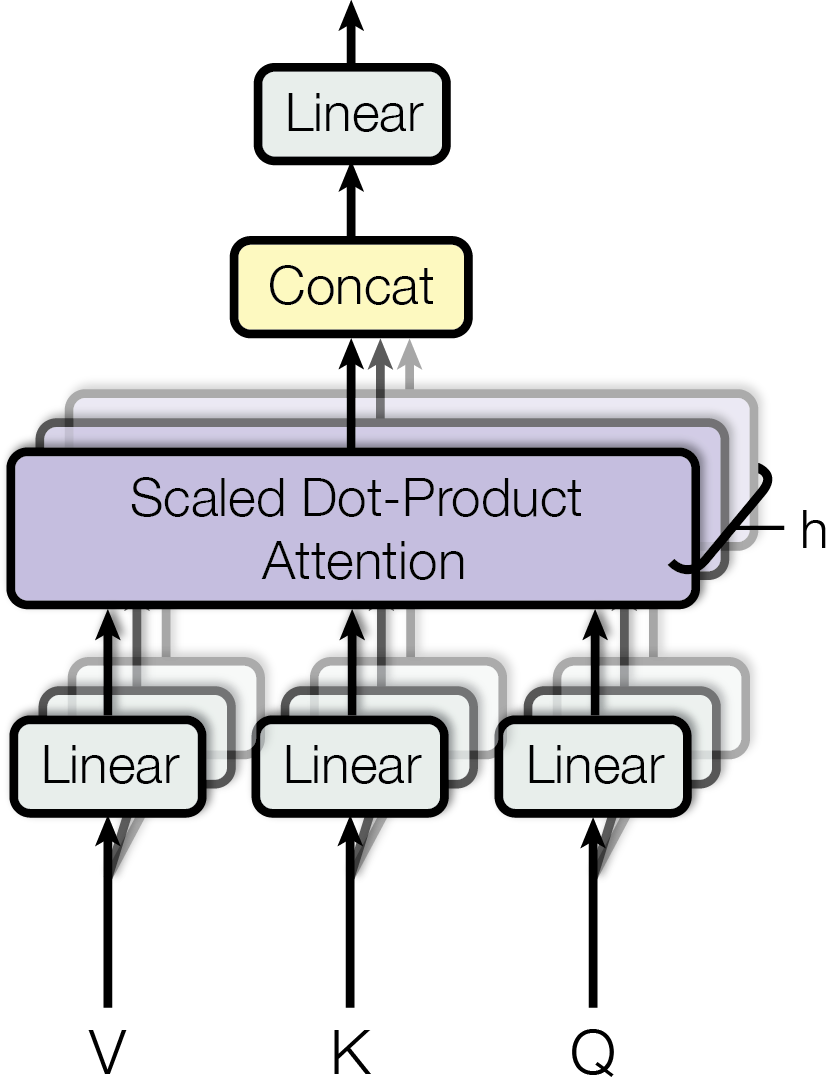
A single attention head can only learn one attention pattern, one way of deciding which tokens are relevant to which. But language requires attending to multiple things simultaneously. A token might need to attend to the previous token (for syntax), to the subject of the sentence (for semantics), and to a matching pattern earlier in the text (for repetition), all at the same time.
The solution is to run multiple attention heads in parallel, each with its own learned projection matrices. Each head has its own , , and , and computes attention independently:
The outputs of all heads are concatenated and projected through a final output matrix :
Why is needed? Because each head operates in a small -dimensional subspace, its output cannot be added directly to the -dimensional residual stream. The output matrix maps the concatenated head outputs back into the full residual stream space. It also lets each head learn how to write its result back: which dimensions of the residual stream to update and with what mixture. In mechanistic interpretability, the combined matrix (the slice of corresponding to head ) is called the OV circuit of a head: it determines what information the head moves from source to destination.
Independent Heads: Each attention head is an independent information-moving operation with its own learned pattern. Head reads from the residual stream, processes it through its own -dimensional subspace, and writes back to the residual stream.
With heads and , the total parameter count is the same as a single large head, but the model can attend to different things at once.The projection to a lower-dimensional space creates a bottleneck. Each attention head operates in a subspace of dimension d_k, which is typically d_model / H where H is the number of heads. This low-rank structure is important for mechanistic interpretability because it means each head can only attend to and move information along a limited set of directions. For mechanistic interpretability, this is a major advantage: we can study each head individually to understand what it does.
In practice, different heads specialize in remarkably specific patterns. Previous token heads consistently attend to the immediately preceding token. Induction heads complete patterns by looking for previous occurrences of the current token and attending to what came after. Name mover heads copy proper names to later positions where they are needed for prediction. We will explore induction heads and other specialized head types in later articles.
To see why multiple heads matter, consider the sentence "The tired cat sat on the mat because it was tired" at the token position "it." Different heads can extract different relationships from the same position simultaneously:
- Head A might attend from "it" back to "cat," resolving the pronoun to its referent.
- Head B might attend from "it" to the first "tired," tracking which property is being referenced.
- Head C might attend from "it" to "sat," tracking the main verb of the clause.
No single head could serve all three purposes at once. Each head's QK circuit determines a different relevance pattern, and each head's OV circuit copies different information. The concatenation of their outputs gives the model simultaneous access to the referent, its property, and the action, all from a single attention layer.
Each attention head is a separate information-moving operation with its own learned pattern. Understanding what each head does is a core goal of mechanistic interpretability.
Pause and think: From architecture to interpretability
If attention heads move information between positions, what determines which information gets moved and where it goes? The query and key matrices determine the "where" (which positions attend to which), while the value and output matrices determine the "what" (which information gets read and written). Decomposing attention into these two circuits, the QK circuit and the OV circuit, is one of the first steps in mechanistic interpretability.
Looking Ahead
Attention is how information moves between positions. But each transformer layer has a second component: the MLP, which transforms information within each position. Where attention routes information, MLPs process it, acting as key-value memories that store and retrieve knowledge. The next article covers how MLPs work and what they compute.
After that, layer normalization addresses the practical complication of keeping activations stable across many layers, and the QK/OV circuit decomposition formalizes the two-circuit structure hinted at above into the mathematical framework that underpins mechanistic interpretability.