From Observation to Causation
Mechanistic interpretability begins with observational tools. The logit lens shows what a model would predict if processing stopped at a given layer. Probing classifiers reveal what information is linearly decodable from the residual stream. Attention patterns display where each head directs its focus. These techniques are powerful, but they share a fundamental limitation: they show what information exists in a model's internals, not what information the model actually uses.
The gap matters. A probing classifier might detect part-of-speech information at 95% accuracy from layer 6 activations, yet removing that information has no effect on the model's downstream performance. The information was there, but the model did not rely on it. Observation reveals correlation. We need causation.
This article introduces the primary tool for establishing causal claims about model internals: activation patching [1]How to Use and Interpret Activation Patching
Heimersheim, S., Nanda, N.
arXiv, 2024. The core idea is straightforward. Replace a specific activation in one model run with the corresponding activation from a different run, and measure the effect on behavior. If the behavior changes, that activation was causally involved in producing the original output.
Observation reveals what exists. Intervention reveals what matters.
The Clean/Corrupted Framework
The basic setup requires two model runs:
- A clean run where the model processes a prompt that produces the desired behavior.
- A corrupted run where the model processes a modified prompt that produces different behavior.
We then replace specific activations from one run into the other and observe how the output changes.
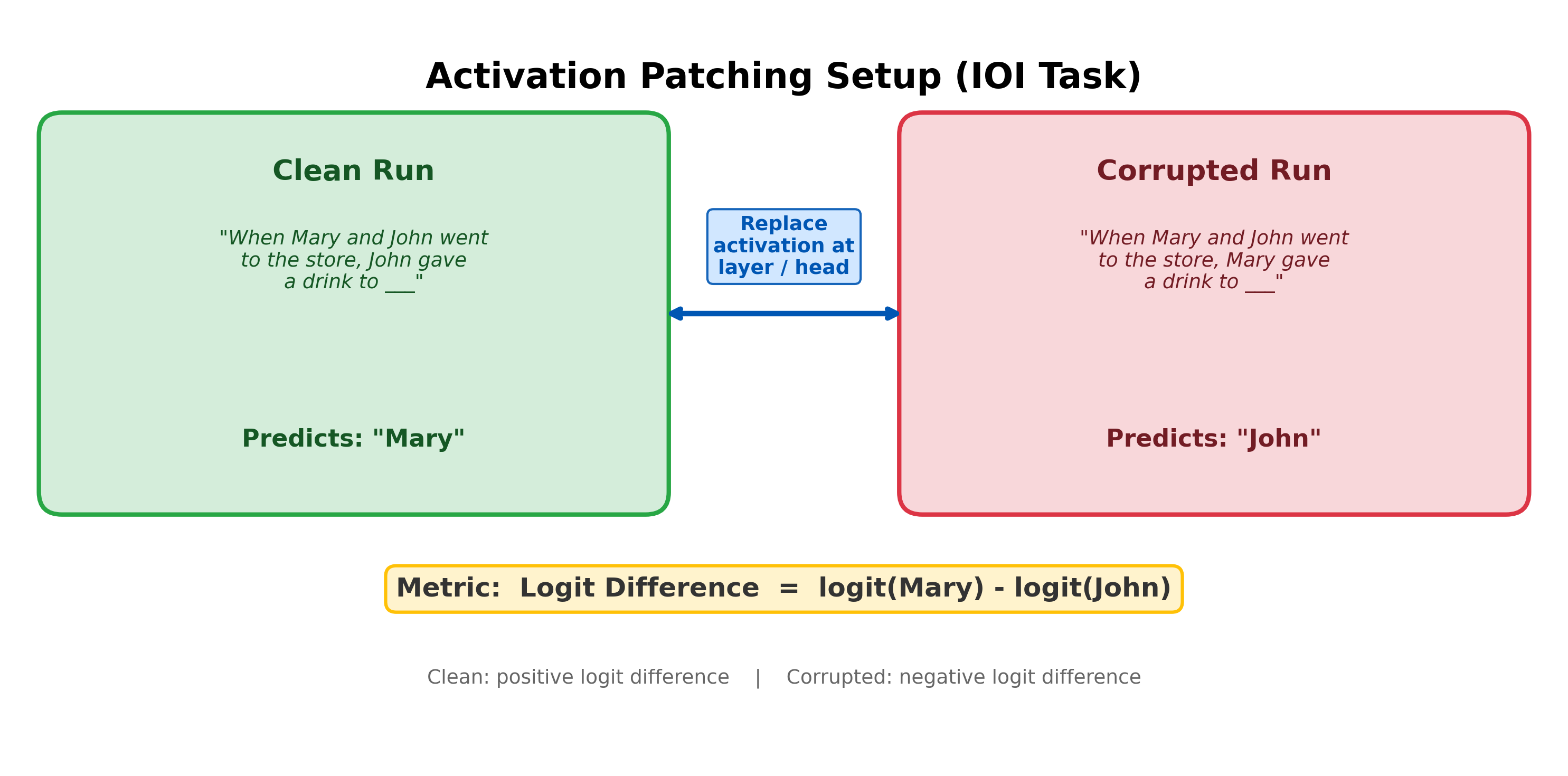
Consider a concrete example from the Indirect Object Identification (IOI) task:
- Clean: "When Mary and John went to the store, John gave a drink to ___" -- the model predicts Mary (the indirect object)
- Corrupted: "When Mary and John went to the store, Mary gave a drink to ___" -- the model predicts John (Mary became the repeated subject, so John is now the indirect object)
Now run the corrupted prompt, but at a specific layer or attention head, replace the corrupted activation with the clean activation. If the model's output switches back toward "Mary", that activation carries information that causally matters for identifying the indirect object. If the output stays at "John", that activation is not important for this task. By repeating this for every layer, every head, and every position, we build a map of what matters.
Activation Patching: Also called causal mediation analysis or interchange intervention, activation patching replaces the activation of a specific model component in one run with the corresponding activation from a different run, while keeping all other components unchanged: . The change in output measures the causal effect of component on the model's behavior for this input pair.
What makes a good clean/corrupted pair? The two prompts should differ in exactly one semantically meaningful way:
- Good: Swap which name is the subject. This changes who the indirect object is with minimal other changes.
- Bad: Use a completely different sentence. Too many confounds make it impossible to tell which difference caused the change.
- Bad: Add random noise to embeddings. The model never encounters this distribution in practice, so the results may not reflect how the model processes natural inputs.
The cleaner the contrast, the more interpretable the results.
Choosing a metric. How do we measure the effect of patching? The preferred metric is the logit difference:
The logit difference is continuous, linear in residual stream contributions, and easy to interpret. Alternatives like probability (nonlinear via softmax, creating artificial sharpness) and accuracy (discrete, hiding gradual effects) are less reliable. Heimersheim and Nanda strongly recommend logit difference, with multiple metrics used to check robustness [2]How to Use and Interpret Activation Patching
Heimersheim, S., Nanda, N.
arXiv, 2024.Activation patching was developed independently by several groups under different names. Vig et al. (2020) introduced 'causal mediation analysis' by applying Pearl's framework to neural NLP. Geiger et al. (2021) formalized 'interchange intervention' within a causal abstraction framework. Meng et al. (2022) used 'causal tracing' with Gaussian noise corruption to trace factual associations. Heimersheim and Nanda (2024) synthesized these approaches into the practical framework now used by the MI community.
Noising vs. Denoising
There are two fundamentally different ways to patch, and the distinction is the most important conceptual point in this article.
Denoising (clean into corrupted): Run the corrupted prompt. Replace one activation with the clean version. This asks: "Can this component restore the correct behavior?" Denoising tests sufficiency -- it identifies components that carry enough information to fix the corrupted run.The distinction between sufficiency and necessity maps directly onto Pearl's causal framework. Denoising identifies sufficient causes -- components whose clean activation alone can restore correct behavior. Noising identifies necessary causes -- components without which the model fails. The two perspectives are complementary, and a complete circuit analysis requires both.
Noising (corrupted into clean): Run the clean prompt. Replace one activation with the corrupted version. This asks: "Does damaging this component break the correct behavior?" Noising tests necessity -- it identifies components that the model cannot do without.
These two directions answer different causal questions, and the difference is not merely academic. Sufficiency and necessity are not the same thing. A component can be sufficient without being necessary (if there are backups), or necessary without being sufficient (if it needs help from other components).
The AND/OR gate analogy. Heimersheim and Nanda offer a clarifying analogy [3]How to Use and Interpret Activation Patching
Heimersheim, S., Nanda, N.
arXiv, 2024:
- Serial circuit (AND gate): A then B then C. Every component is necessary. Noising any one breaks the circuit.
- Parallel circuit (OR gate): A or B or C. No single component is necessary because the others compensate, but each is sufficient alone.
Noising finds AND-circuit components (serial dependencies). Denoising finds OR-circuit components (parallel/redundant paths).
This matters enormously in practice. The IOI circuit in GPT-2 has backup Name Mover heads that activate when the primary Name Movers are disabled. If you only use noising, you might miss the primary Name Movers entirely because the backups compensate. If you use denoising, you correctly identify the Name Movers as sufficient.
The takeaway: always consider which direction you are patching and what question it answers. A component that looks unimportant under one direction may be critically important under the other.
Pause and think: Redundant components
Consider a circuit with two redundant components A and B that each independently produce the correct output. What does noising A show? What does denoising A show? Which gives you more useful information about the circuit's structure?
Noising A would show little or no effect, because B compensates. Denoising A would show a large effect, revealing that A alone carries enough information. In circuits with redundancy, denoising is more informative for identifying individual components.
Ablation: Choosing a Baseline
Activation patching substitutes an activation from one specific run into another. But sometimes we want to ask a simpler question: "What happens if this component contributes nothing?" This is ablation: replacing a component's activation with some baseline value to test whether the model needs it.
Ablation: Replacing a model component's activation with a fixed baseline value (rather than a value from a specific alternative run) to test whether the component is necessary for a behavior. Ablation tests necessity: if performance degrades, the component matters.
The choice of baseline is not obvious, and it affects results in practice.
Zero ablation sets the component's output to the zero vector. This is the simplest option: it removes the component's additive contribution to the residual stream entirely. But zero is often far from the model's natural activation distribution. Downstream components receive an input they would never see during normal operation, so the observed effect may partly reflect the model's response to an out-of-distribution input rather than the component's genuine contribution.
Mean ablation replaces the activation with its mean over a dataset of inputs. The intuition: the mean activation represents the component's "average" contribution. Replacing with the mean removes the component's input-specific signal while preserving its average effect on the residual stream. This keeps downstream activations closer to their natural distribution than zero ablation does.In practice, mean ablation and zero ablation often agree on which components are important, but they can disagree on magnitude. Components whose mean activation is far from zero -- common for MLP layers, which often have a large constant bias term -- show substantially different ablation effects under the two methods.
Resampling ablation replaces the activation with the value from a random different input. This preserves the full distribution of the component's activations, not just the mean. Each ablation sample draws from the same distribution the model normally encounters, avoiding distribution shift entirely. This is more expensive (you need multiple samples to get stable estimates) but more principled. Resampling ablation is used in the causal scrubbing framework, which formalizes circuit hypotheses as claims about which activations can be freely resampled without changing behavior.
In current practice, mean ablation is the most common default: it is cheap, stays near the natural distribution, and produces reliable results for most components. The key takeaway is that ablation baseline choice is a methodological decision, and results should be interpreted with that choice in mind.
Corruption Methods Matter
The choice of how to construct the corrupted input is at least as consequential as the choice of ablation baseline. Zhang and Nanda [4]Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
Zhang, F., Nanda, N.
ICLR, 2024 demonstrated that different corruption methods applied to the same model on the same task can lead to substantially different conclusions about which components matter.
Symmetric Token Replacement (STR) constructs corrupted prompts by swapping key tokens with semantically matched alternatives: "The Eiffel Tower is in [Paris]" becomes "The Colosseum is in [Rome]." Both prompts are perfectly valid sentences the model would encounter naturally, so internal mechanisms operate normally on both. The corruption changes only which factual information the model needs to recall.
Gaussian noise (GN), used by Meng et al. in their ROME causal tracing work, adds noise drawn from to token embeddings. This is simpler to implement (no need to construct paired prompts), but the resulting embeddings are far outside the training distribution.
The difference in results is striking. For factual recall in GPT-2 XL, GN produces a salient peak of MLP importance around layer 16 (the famous "early site / late site" pattern from ROME). STR shows no comparable peak on the same model and task. GN peak values were 2-5x higher than STR across multiple analysis configurations. The localization pattern that motivated ROME's design may be partly an artifact of the corruption method.
Why does GN produce inflated results? Zhang and Nanda traced the problem to out-of-distribution activation propagation. Under GN corruption, attention patterns in downstream heads break: Name Mover heads that normally attend to the indirect object with 0.58 probability split their attention diffusely. When upstream components are patched (restored) in a GN-corrupted run, they cannot fix the downstream damage because intermediate components have already been pushed into abnormal operating regimes. Under STR, patching upstream components cleanly restores downstream behavior because all components are operating in-distribution throughout.This finding has practical implications for the ROME literature. The strong localization of factual knowledge to specific MLP layers, which motivated ROME's design choice to edit only mid-layer MLPs, may be partly a consequence of Gaussian noise corruption rather than a faithful reflection of how the model processes facts. This does not invalidate ROME as an editing technique, but it does complicate the interpretability claims that motivated it.
Metric choice matters too. Probability as a metric cannot detect negative components (heads that actively hurt performance), because it is bounded below by zero. When the corrupted-run probability of the correct token is already near zero, components that make things worse cannot reduce it further. Logit difference has no such floor. Zhang and Nanda found that probability and logit difference identify different sets of important heads on the IOI task, with probability missing all three Name Mover heads under some configurations.
The practical takeaway: default to STR when possible, and use logit difference as the primary metric. Fall back to Gaussian noise only when constructing in-distribution paired prompts is impractical (e.g., when there is no natural symmetric replacement). Report methodological choices explicitly, since they materially affect conclusions.
A Worked Example: IOI in GPT-2 Small
Let us walk through activation patching on the Indirect Object Identification task in GPT-2 Small. This worked example demonstrates the full patching workflow and reveals the sparse circuit structure that makes mechanistic interpretability possible.
Step 1: Establish the baseline. On the clean prompt, the model correctly predicts "Mary" with a positive logit difference:
On the corrupted prompt (where the subject names are swapped), the model predicts "John" with a negative logit difference:
The gap between these two values is what we want to explain: which internal components drive this behavioral difference?
Step 2: Patch layer by layer. For each layer , we replace the corrupted residual stream with the clean one (denoising direction) and measure how much of the logit difference is recovered.
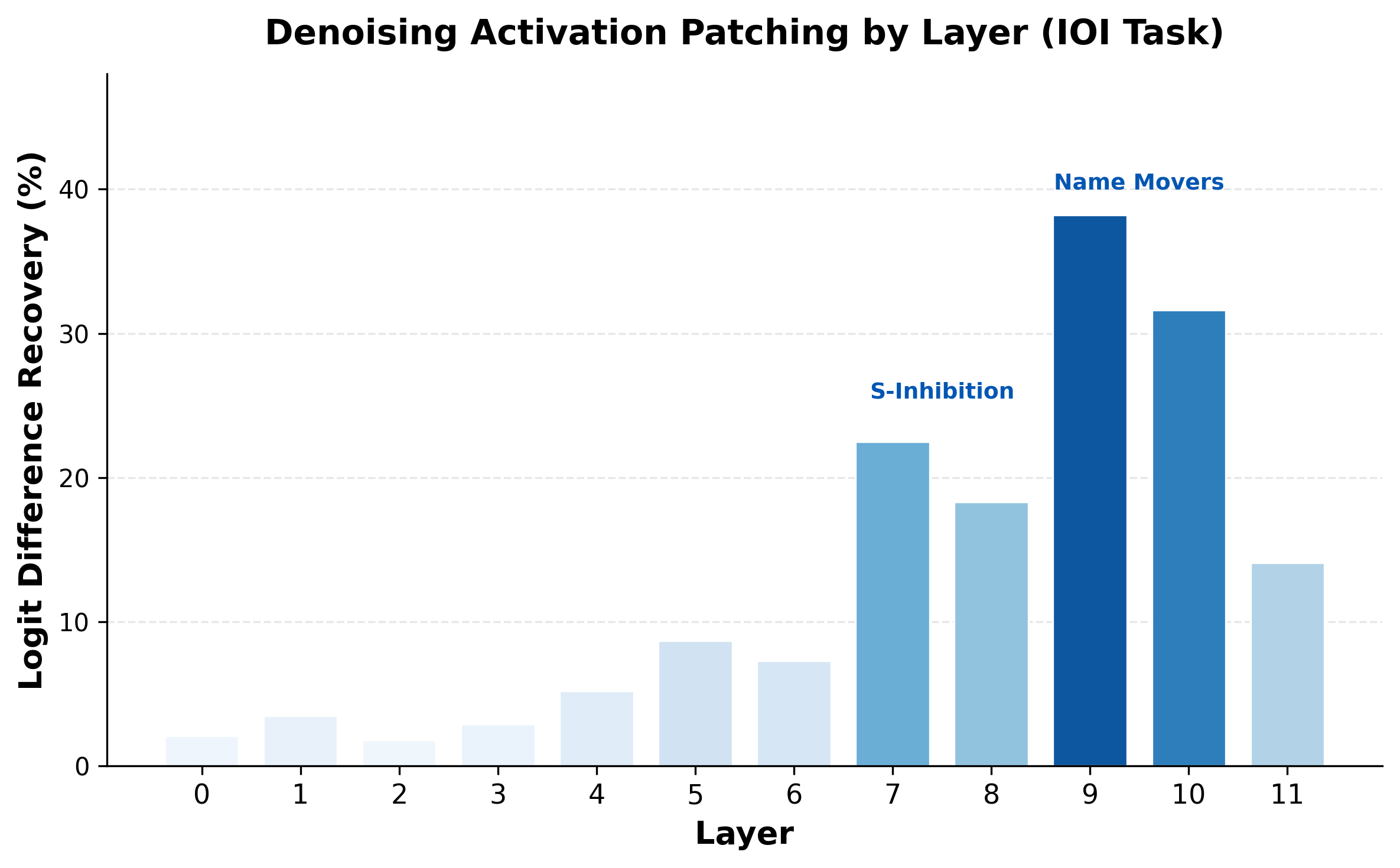
The results tell a clear story:
- Layers 0-4: Small effect. Early processing (token embeddings, positional information) does not contribute much on its own.
- Layers 5-6: Moderate effect. Induction-style heads begin to contribute.
- Layers 7-8: Large effect. This is where the S-Inhibition heads operate, suppressing attention to the duplicated name.
- Layers 9-10: The largest effect. The Name Mover heads directly copy the indirect object name to the output logits.
Step 3: Patch individual attention heads. The layer-level results show where in the model the critical computation happens, but not which specific components are responsible. For each of the 144 attention heads (12 layers times 12 heads), we patch the corrupted head output with the clean one and measure recovery.
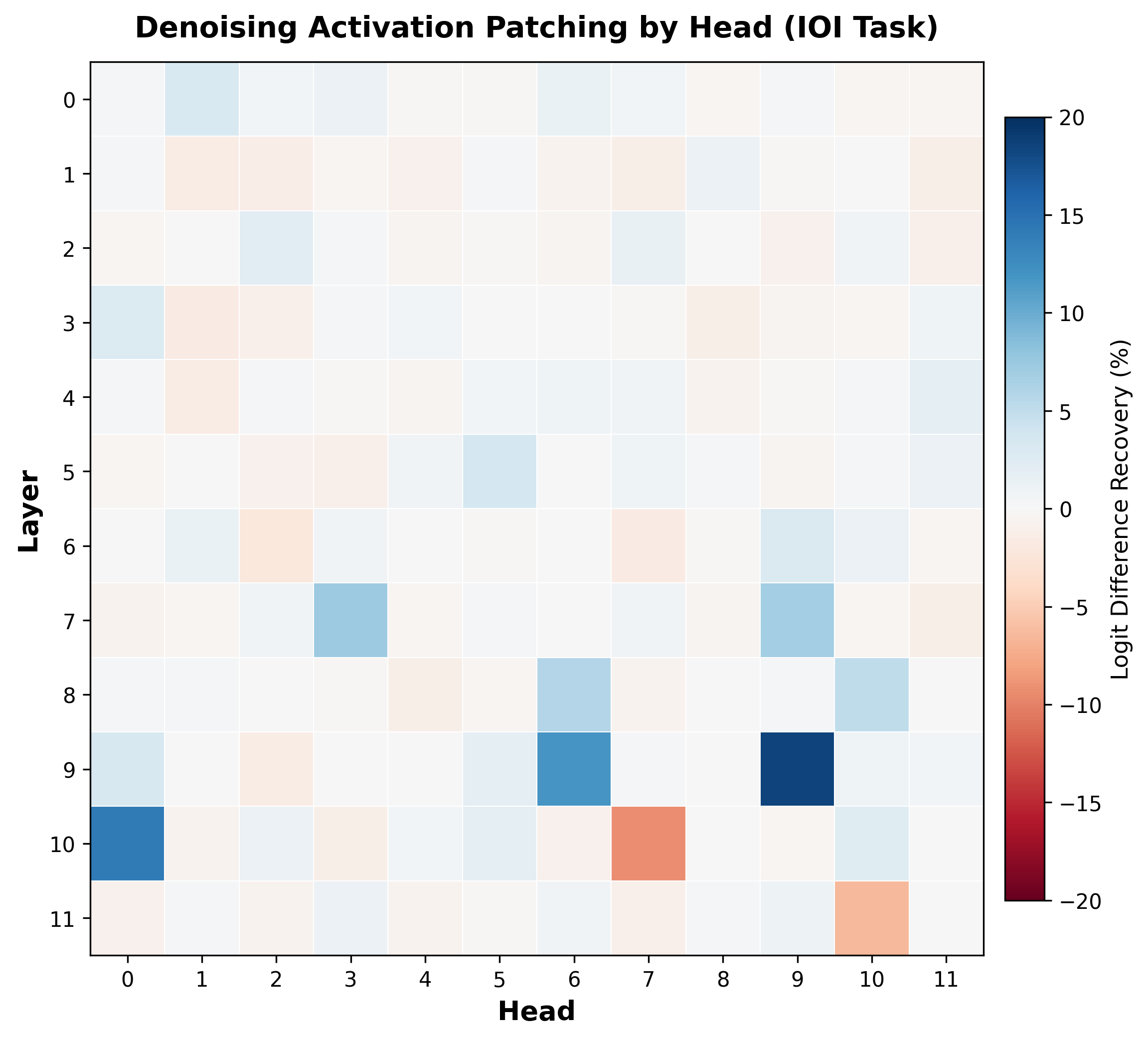
The heatmap reveals a remarkably sparse structure. Most heads have near-zero effect, but a handful stand out:
Blue cells (positive effect): These are the key players. Heads 9.9, 10.0, and 9.6 are the Name Mover heads, each recovering a large fraction of the logit difference. Heads 7.3, 7.9, 8.6, and 8.10 are the S-Inhibition heads, which suppress the wrong answer.
Red cells (negative effect): Equally informative. Heads 10.7 and 11.10 are Negative Name Movers that write against the correct answer. This is a counterintuitive but real phenomenon -- some heads consistently hurt performance on this task, actively pushing the model toward the wrong prediction.
Interpretation. A small number of heads -- roughly 10-15 out of 144 -- account for nearly all of the IOI behavior. This is a structured circuit, not random distributed computation. The key insight is that patching identified the circuit's components without any prior knowledge of what the model was doing. We did not need to know about Name Movers or S-Inhibition heads in advance -- the patching results revealed them purely through causal evidence.
For the full analysis of how these heads work together to implement an algorithm for identifying the indirect object, see Wang et al. [5]Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Wang, K., Variengien, A., Conmy, A., et al.
arXiv, 2022.
A note on interpreting recovery percentages. When we say "patching head 9.9 recovers 38% of the logit difference," this means replacing the corrupted activation of head 9.9 with its clean activation restores 38% of the gap between clean and corrupted performance. This does not mean head 9.9 is "38% of the circuit." Multiple components may independently recover overlapping portions, so the recoveries do not necessarily add up to 100%. Be careful with arithmetic interpretations of patching results -- they measure causal importance, not a partition of credit.
Pause and think: Designing a patching experiment
You have a model that correctly identifies sentiment in movie reviews. You want to know whether the model relies on specific adjectives or on overall sentence structure. How would you design an activation patching experiment to test this? What would your clean and corrupted prompts look like?
A good approach: use clean prompts with clear sentiment ("This movie was absolutely brilliant") and corrupted prompts where the adjectives are replaced with neutral or opposite ones while preserving sentence structure ("This movie was absolutely terrible"). If patching the early layers (where token identity is processed) recovers the sentiment, the model relies on the specific words. If patching later layers matters more, the model may depend on higher-level structural features.
Attribution Patching
Full activation patching requires a separate forward pass for every component you want to test. In GPT-2 Small with 144 attention heads and 12 MLP layers, that means 156 forward passes. In GPT-3, with roughly 4.7 million neurons, testing each one individually is impractical. The problem is even worse at the neuron level: individual neurons are often polysemantic, responding to multiple unrelated features due to superposition, so head-level patching may miss important structure. Can we approximate patching without running all those forward passes?
Attribution patching [6]Attribution Patching: Activation Patching At Industrial Scale Using Differential Calculus
Nanda, N.
Blog post, 2023 uses a first-order Taylor approximation to estimate what full patching would find. The gradient of the metric with respect to each activation tells us how sensitive the output is to changes at that location. The difference between the clean and corrupted activations tells us how much each activation actually changes. Their product approximates the full patching effect:
The efficiency gain is enormous. Full activation patching requires forward passes, one per component. Attribution patching requires only two forward passes plus one backward pass for all components simultaneously. For GPT-3 with 4.7 million neurons, that is 3 passes instead of 4.7 million.
When does this approximation work? Transformers are, as Nanda puts it, "shockingly linear objects." The linear approximation often holds well for small activations like individual head outputs and neurons, where the relationship between activation changes and metric changes is approximately linear.
When does it break? For large activations such as entire residual streams at a layer, nonlinearities from softmax, MLP activations, and LayerNorm invalidate the linear regime. The Taylor approximation assumes small perturbations, and patching an entire layer's residual stream is anything but small.
Best practice: Use attribution patching as a fast screening tool. Sweep the entire model in a single pass to identify the most promising components, then verify the top candidates with actual activation patching. Think of it as a microscope's low-magnification mode -- scan the whole slide quickly to find the interesting regions, then switch to high magnification for precise measurement.
For a deeper treatment of attribution patching, including its relationship to path patching and how both are applied at scale, see Attribution Patching and Path Patching.
Path Patching
Standard activation patching replaces a component's entire output. But a head's output flows to many downstream components through the residual stream. Head might send critical information to head but irrelevant information to head . Standard patching cannot distinguish these pathways.
Path patching asks a more refined question: which specific pathway carries the critical information? Instead of patching head 's output everywhere, patch only the part of 's output that flows to a specific downstream component . This isolates the direct connection from other paths through the residual stream.
The shift is from nodes to edges in the computational graph. Activation patching tests whether component is important. Path patching tests whether the specific connection is important. This finer resolution reveals the wiring of the circuit, not just which components participate.
Path patching was central to the IOI circuit analysis [7]Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 Small
Wang, K., Variengien, A., Conmy, A., et al.
arXiv, 2022, where it revealed how information flows between the head classes: from Duplicate Token heads through S-Inhibition heads to Name Mover heads. Without path patching, we would know which heads matter but not how they communicate.
Conmy et al. extended this idea into the ACDC algorithm (Automatic Circuit DisCovery), which automates path patching to systematically prune edges and discover circuits [8]Towards Automated Circuit Discovery for Mechanistic Interpretability
Conmy, A., Mavor-Parker, A. N., Lynch, A., et al.
NeurIPS, 2023. ACDC starts with a fully connected computational graph and iteratively removes edges whose patching effect falls below a threshold, leaving behind the minimal circuit.
Confounds: Self-Repair and Compensation
Activation patching is the gold standard for causal claims about model internals, but it has a systematic blind spot: self-repair. When we ablate or patch a model component, later components may compensate, partially restoring the original behavior. The effect we measure understates the component's true importance.
Several mechanisms contribute to self-repair. LayerNorm rescaling accounts for a significant fraction: when a component's contribution is removed from the residual stream, the magnitude of the stream changes, and LayerNorm renormalizes it. This mechanical rescaling can recover up to 30% of the ablated effect without any "intelligent" compensation [9]The Hydra Effect: Emergent Self-repair in Language Model Computations
McGrath, T., Rahtz, M., Kramar, J., et al.
arXiv, 2023. Backup components provide another source: heads that are nearly inactive under normal operation activate when primary components are removed, picking up their function. The IOI circuit's Backup Name Movers are the canonical example. Beyond these identified mechanisms, a substantial fraction of self-repair remains unexplained [10]Explorations of Self-Repair in Language Models
Rushing, C., Nanda, N.
arXiv, 2024.
The practical consequence: ablation effects are a lower bound on component importance. A component that appears to account for 30% of the logit difference when ablated may actually be responsible for substantially more, with the gap hidden by downstream compensation. This is particularly problematic for noising experiments, where the clean run's backup mechanisms are fully operational and ready to compensate.
Resample ablation (replacing a component's activation with the value from a random different input) provides a better baseline than zero ablation for exactly this reason. It preserves the activation distribution that downstream components expect, reducing the confound from out-of-distribution inputs triggering abnormal compensation. Mean ablation offers a similar advantage at lower cost.
For a deeper treatment of self-repair as a general phenomenon, including the known mechanisms and open questions, see Self-Repair in Language Models.
The Causal Toolkit
We now have three levels of causal analysis, each suited to a different stage of investigation:
- Activation patching tests which components matter by replacing entire activations. It operates at the node level.
- Attribution patching provides fast screening of all components through gradient approximation, making it practical to survey even the largest models.
- Path patching tests which connections between components matter, operating at the edge level.
Together, these tools let us progress from "something is happening at layer 9" to "head 9.9 sends indirect-object information to the output through a specific pathway" -- the kind of mechanistic understanding that gives this field its name. To see these tools applied at scale, continue to the IOI circuit, the most complete circuit analysis ever performed.